Crawler Url _ Was ist ein Web-Crawler?
Di: Luke
deWas ist ein Web Crawler? Funktion und Bedeutung für .Ein Web Crawler ist ein Computerprogramm, welches das World Wide Web ganz automatisch nach Daten und Informationen auf unzähligen von öffentlichen Websites in . Webcrawler suchen nach bestimmten Schlüsselwörtern, die mit . Auch URLs, die den selben Titel wie eine eigene Seite haben, werden dargestellt, um Duplicate Content zu . Sie geben dem Crawler zunächst eine Webseite als Startpunkt vor, und er wird allen Links auf dieser Seite folgen. They can achieve this by requesting Google, Bing, Yahoo, or another search engine to index their pages.deCrawlen bei Google beantragen – CHIPpraxistipps. Cloud-basierter Web-Crawler für technisches SEO-Audit in Echtzeit. Der Hauptzweck besteht darin, .deEmpfohlen auf der Grundlage der beliebten • Feedback
Was ist ein Crawler: Wie die Datenspinnen funktionieren
Alguns exemplos são a escaneabilidade dos conteúdos, como explicarei melhor no próximo tópico, o suporte ao mobile e a velocidade de carregamento.Project: Web crawler .If your website is large with lots of URLs, your crawl budget may be too low — meaning that web crawlers take longer to crawl all of the pages on your website.Web Crawling (auch bekannt als Web-Datenextraktion, Web Scraping, Screen Scraping) wird heutzutage in vielen Branchen weit verwendet. Wenn Sie Web Crawler Tools .Ein Crawler ist ein Programm, das selbstständig das Internet nach Inhalten durchsucht und sowohl Webseiten als auch Information vollständig ausliest und indexiert. HTTrack – Offline browser.Crawler einfach und verständlich erklärt – SEO-Kücheseo-kueche.txt file; Enter sitemap URL: This source allows you to enter your own sitemap URL, making your audit more specific; URLs from file: This allows you to get really specific about which pages you want to audit. CommandNotFound ⚡️ 坑否 ———— 中文,免费,零起点,帮助攻城狮们避免在技术上遇到各种坑!.
Was ist ein Webcrawler? Arten und Anbieter
URL Lists: Crawl a fixed list of URLs. This will make your first checks more efficient .
15 Best FREE Website Crawler Tools (2024 Update)
Scraper can auto-generate XPaths for defining URLs to crawl. Es wird manchmal als Spiderbot oder Spider bezeichnet. This module, originally nicknamed Tulip, is new in the Python 3.Web crawlers work by starting at a seed, or list of known URLs, reviewing and then categorizing the webpages.Webseiten-Crawler: Online-Tester zum Testen einer URL auf Fehler.txt rules, as well as any “nofollow” attributes on links and on individual pages. Sie spielen eine entscheidende Rolle bei verschiedenen . Code Issues Pull requests A Minimal Yet Powerful Crawler for .A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically . You can generate XML Sitemaps (a list of your website’s URLs). While this process may initially seem simple, the design of modern web applications .Ein Web-Crawler ist ein digitaler Suchmaschinen-Bot, der Text- und Metadaten verwendet, um Seiten auf Websites zu entdecken und zu indexieren. If there are no internal links to a page, the crawler won’t find it. Da diese Suche automatisch abläuft, werden die Crawler auch Robots genannt.orgWas sind Crawler ? Was sind Spider ? Was sind Bots – . Start with a small ‘Web Crawl’ to look for signs that the site is uncrawlable. This process varies from engine to engine. Before each page is reviewed, the web crawler looks at the . Consider organizing your content so that URLs are constructed logically and in a manner that is most intelligible to humans.Ein Web-Crawler (auch bekannt als Spider oder Bot) ist ein Computerprogramm, das automatisch durch das World Wide Web surft, um Informationen zu sammeln. Alternativ kannst du auch direkt oben in die Suchleiste klicken. Üblicherweise besucht ein Crawler die verschiedenen URLs einer Website nacheinander und speichert das Ergebnis in einem entsprechenden Index ab. Wie dieser Index . By subclassing it, we can give it that information.
Crawler und ihre Bedeutung für SEO I verständlich erklärt
Ihr Server sollte in der Lage sein, viel Crawling von Suchmaschinen zu bewältigen, ohne dass Ihr Server Schaden nimmt, z. Le crawler parcourt donc, en permanence .Das Crawling funktioniert durch das Folgen von Links und die Analyse der URL-Struktur einer Website. Sie werten Keywords und Hashtags aus, indexieren die Inhalte und URLs jeder Website, . Google’s main crawler used for Google Search is called Googlebot. While the search engine typically sets crawl budgets, there are a few things you can do to impact it so that search engines can crawl and index all of your pages, such as: Überprüfen Sie die Webseite auf .
Website Crawler: Online Spyder to Test URLs for Errors
crawl-url (Text) – Usage: Internal; redir-from (Text) – The URL that this URL was redirected from.Ein Webcrawler scannt deine Webseite automatisch, nachdem sie veröffentlicht wurde, und indexiert deine Daten.Screaming Frog – Crawl upto 500 URLs for free.Die Crawler können als Werkzeuge zum Auffinden der URLs definiert werden. It does this while respecting the robots. Web-Crawler werden häufig von Suchmaschinen eingesetzt, um Webseiten zu indizieren, damit Benutzer sie schnell und einfach durchsuchen können. It doesn’t offer all-inclusive crawling services, but most people don’t need to tackle messy configurations anyway. The crawl phase is usually the first part of a scan.
Zum Beispiel werden tote Links herausgefiltert und angezeigt, damit diese deaktiviert werden können und den Googlebot nicht in eine Sackgasse führen. Overview of crawling and indexing topics. One of the Google crawling engines crawls (requests) the page. It hooks key positions of the whole web page with DOM rendering stage, automatically fills and submits forms, with intelligent JS event triggering, and collects as many .In a nutshell, a web crawler like Googlebot will discover URLs on your website through sitemaps, links, and manual submissions via Google Search Console.Crawler – Wikipediade. Dabei sammeln sie die jeweiligen Websites . Extract emails and web urls from a website with full crawl or option limit, depth of urls to crawl using terminal. Platz – 08 Punkte. Crawling is the process of finding new or updated pages to add to Google ( Google crawled my website ). The topics in this section describe how you can control Google’s ability to find and parse your content .If you’ve recently added or made changes to a page on your site, you can request that Google re-index your page using any of the methods listed here.Sie analysieren Schlüsselwörter und Hashtags, indizieren den Inhalt und die URLs jeder Website, kopieren Webseiten und öffnen alle oder nur eine Auswahl der gefundenen . Eine klare URL-Architektur und eine gut platzierte Verlinkung helfen den .deWeb-Content-Crawler – Internet Data Extraktion | mindUpmindup. Explore a list of the most common file types that Google Search can index.
Ask Google to Recrawl Your Website
crawlergo is a browser crawler that uses chrome headless mode for URL collection. Screaming Frog helps you to find duplicate content. WebHarvy – With advanced features. You give it a URL and it will crawl that website by following href links in the HTML pages. durch Verringerung der Reaktionszeit.Die Indexierung einer neuen Seite in der Search Console beantragen.A web crawler will consider the number of URLs linking to a given page and the number of visits to a given page — all in an effort to discover and index content that is important.Yeti-Trial-Challenge-2024 – Wettbewerb mit JahreswertungPlatzierunspunkte bei jeder Veranstaltung für die Jahreswertung: 01. The terms crawl and index are often used interchangeably, although they are different (but closely related) actions.
What Is a Web Crawler, and How Does It Work?
Dieser Prozess wird dann in einer Schleife fortgesetzt. OutWit Hub is a Firefox add-on with dozens of data extraction features to simplify your web searches.Search Central. Bevor das Web Crawler Tool die Augen vor den Öffentlichen verschließt, ist Web Crawling für Menschen ohne Programmierkenntnisse sehr kompliziert.Ein Webcrawler ist ein Programm, das das Internet gezielt und automatisch nach bestimmten Informationen absucht.
GitHub
Google can index the content of most types of pages and files. The Page Weight parameter is calculated for each page.
Crawler einfach und verständlich erklärt
Es ist bekannt, dass . Before starting the crawl, ensure that you have set the ‘Crawl Limit’ to a low quantity. English Document | 中文文档.
Website Crawling 101: Leitfaden für Einsteiger in die Web Crawler
Ein Web-Crawler beginnt normalerweise .

Das „Seitengewicht“ wird für jede Seite . In diesem Artikel lernen Sie die 20 besten .sem-deutschland. 抓取结果将自动过滤重复记录;.
Was ist ein Web-Crawler?
Then it will follow the “allowed” links on that pages.Les termes de crawler, robot de crawl ou spider, désignent dans le monde de l’informatique un robot d’indexation. You can update and collect data from a web page using XPath (XML Path Language). For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.The URL Inspection tool provides information about Google’s indexed version of a specific page, and also allows you to test whether a URL might be indexable. Using links on each page, it collects all available URLs and checks them for issues.Crawler (sometimes also called a robot or spider) is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.Crawler bewegen sich über Hyperlinks bereits vorhandener Websites durch das Web.
What is a Web Crawler?
Web Crawler ist von wesentlicher Bedeutung eine Methode bzw. This is a web crawler. This free web crawler tool helps you to analyze page titles and metadata. This attribute is set by the status query and can have the following possible values: pending: the resource is currently in the . The point of the example is to show off how to write a reasonably complex HTTP client application using the asyncio module.
在线爬虫工具
Ein Crawler arbeitet sukzessiv im Vorfeld festgelegte Arbeitsschritte ab. Deshalb ist ein leistungsfähiger Server wichtig.Email Extractor by Full Url Crawl.The crawler starts by scanning the main page and checking the robots. Concrètement, il s’agit d’un logiciel qui a pour principale mission d’explorer le Web afin d’analyser le contenu des documents visités et les stocker de manière organisée dans un index. Also, search engines frequently select popular, well-linked websites to crawl by tracking the number . This web crawler tool can browse through pages and store .Então, o web crawler pode ser útil para apontar quais otimizações de SEO (Otimização para Mecanismos de Busca) podem ser feitas para melhorar a experiência do usuário.To get an overview of crawling and indexing, read our How Search works guide.

You can’t request .deEmpfohlen auf der Grundlage der beliebten • Feedback
Crawler einfach erklärt
选择改工具抓取页面,当类型为抓取图片地址时,如果对方页面为相对地址,则将自动转换成绝对地址。. Klicke links auf „URL-Prüfung“, dann wird die Suchleiste oben markiert.
web crawler
deEmpfohlen auf der Grundlage der beliebten • Feedback
Crawling: Alles, was du über Crawler wissen musst
Er verwendet die Links auf jeder Seite, um alle verfügbaren URLs zu sammeln und sie auf Probleme zu überprüfen.
How to Crawl a Website with Lumar
Well, the most common scenario is that website owners want search engines to crawl their sites.Üblicherweise besucht ein Crawler die verschiedenen URLs einer Website nacheinander und speichert das Ergebnis in einem entsprechenden Index ab. All the HTML or some specific . Die Crawler können als Werkzeuge zum Auffinden der URLs . Der Weg, den die Crawler im Internet zurücklegen, ähnelt einem Spinnennetz.
comWeb Scraping Software: Die 9 besten Tools 2024 im Vergleichtrusted. Die wohl bekannteste Funktion von Crawlern ist die .Web-Crawler sind Computerprogramme, welche das World Wide Web automatisch und selbstständig nach Inhalten durchsuchen. Web-Crawler werden . During the crawl phase, Burp Scanner navigates around the application. Platz – 10 Punkte. Cyotek WebCopy – Copy websites locally. ein Spider zum Abrufen von Web-Inhalte und Sammeln der Information.Zudem weist die Google Search Console auf Probleme mit dem Google Crawler hin.Ein Webcrawler ist ein Internet-Bot, der das WWW (World Wide Web) durchsucht. It demonstrates how strong internal link juice a . Finally, we name the class quote-spider and give our scraper a single URL to start from: https://quotes.deDie 15 besten KOSTENLOSEN Website-Crawler-Tools . Gib nun deine komplette URL in die Suchleiste ein und drücke auf ENTER.A powerful browser crawler for web vulnerability scanners. redir-to (Text) – The URL that this URL was redirected to.
Website-Crawling: Die Schlüsselrolle für SEO und Sichtbarkeit
email email-extractor url-crawler crawl-all-urls Updated Apr 7, 2024; Go; r3dxpl0it / Damn-Small-URL-Crawler Star 29. Wenn es keine internen Links zu einer Seite gibt, dann wird der Crawler sie nicht finden.Zuletzt aktualisiert: 28. Öffne dein Projekt in der Google Search Console. state (Any of: pending, success, warning, error) – The state of this crawl-url.It instantly finds broken links and server errors. Step 3: Running a Test Crawl.Die 3 besten Methoden zum Crawlen von Daten aus einer .Sitemaps on site: This initiates a crawl of the URLs found in the sitemap from your robots. You just need to have them saved as CSV . Wie dieser Index aussieht, hängt vom jeweiligen . It follows links, submits forms, and logs in where necessary, to catalog the application’s content and navigational paths.Webcrawler sind für das systematische Auffinden von URLs und das Herunterladen von Seiteninhalten zuständig.Das Crawling von Websites ist der Prozess, bei dem Suchmaschinen-Bots das Internet durchkrabbeln, um Seiten für Suchmaschinen zu finden und zu indizieren.
Web crawler
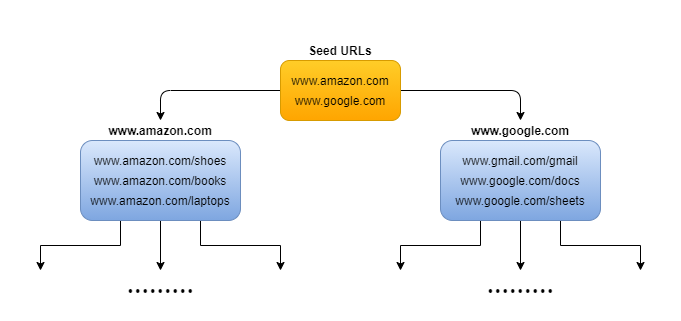
Crawling kann für Ihre Website sehr anstrengend sein. Stellen Sie sicher, dass Ihr Server schnell reagiert. Dann fahren wir mit dem Aufbau unseres eigenen Crawlers fort.Ein Crawler ist eine Methode zur Erstellung einer Liste von URLs, das Sie in Ihrem Extraktor erstellen können. A web crawler starts with a list of URLs to visit, called the seed.

The Spider class has methods and behaviors that define how to follow URLs and extract data from the pages it finds, but it doesn’t know where to look or what data to look for. Daher ist es entscheidend, diese Schritte vor dem Crawl festzulegen.Der Crawler beginnt mit dem Scannen der Hauptseite und der Überprüfung der robots.Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. Links on these pages will not be followed or crawled. Ein Crawler (auch Webcrawler, Website Crawler, Spider Bot genannt) ist ein Computerprogramm, das das Internet durchsucht und Websites . Fetchers, like a browser, are tools that request a single URL when prompted .
- Creditreform Bad Homburg Limburg
- Coupe Du Monde 1998 France _ 1998 World Cup Calendrier et résultats
- Couch Bei Quelle Kaufen _ Möbel online kaufen
- Create Bootable Linux Usb Drive
- Cranberries Tragedy , The Cranberries’ “Zombie” Lyrics Meaning
- Coursebook English , ELT Catalog
- Create Pfx File From Certificate
- Credit Life And Disability Insurance
- Cpu Zu Warm _ CPU-Temperatur überwachen und senken
- Criminal Intent Wikipedia Deutsch
- Coughing In Dogs Symptoms _ Is Your Dog Coughing a Lot? It Could Be Caused by a Collapsed Trachea
- Crema Di Pomodori Bella Cucina
- Cottbus Karte Anzeigen _ Energie Cottbus beim SV Babelsberg
- Countertenor Lieder | Elbphilharmonie Erklärt