Cross Entropy Loss Examples | Using weights in CrossEntropyLoss and BCELoss (PyTorch)
Di: Luke
In this tutorial, you will train a logistic regression model using cross-entropy loss and make predictions on test data. randn ( 3 , 5 , requires_grad = True ) >>> target = torch .Focal loss achieves this through something called Down Weighting.
Cross-Entropy for Dummies
Other loss functions that penalize errors differently can be also used for training, resulting in models with different final test accuracy.Cross-Entropy Loss Functions: Theoretical Analysis and Applications.Cross-Entropy Loss: Make Predictions with Confidence. ML Foundations. Cross-entropy is a widely used loss function in applications. CrossEntropyLoss () >>> input = torch .BCELoss(weights=weights) You can find a more concrete example here or another helpful PT forum discussion here.

e, the smaller the loss the better the model. The cross-entropy loss function is .
Cross-Entropy Loss: Make Predictions with Confidence
Vlastimil Martinek. The current API for cross entropy loss only allows weights of shape C. Unfortunately, because this combination is so common, it is often abbreviated. A lower loss for a sample indicates a more accurate prediction, while a higher loss suggests a larger discrepancy.02: Great probabilities.Cross-entropy loss, also known as negative log likelihood loss, is a commonly used loss function in machine learning for classification problems.Cross-entropy is commonly used as a loss function for classification problems, but due to historical reasons, most explanations of cross-entropy are based on communication theory which data ., mean for averaging, sum for total loss, none for individual losses). Categorical Cross-Entropy Given One Example.Pytorch中CrossEntropyLoss ()函数的主要是将softmax-log-NLLLoss合并到一块得到的结果。. Cross Entropy Loss: Intro, Applications, Code. Have you ever wondered what happens under the hood when you train a neural network? You’ll run the gradient .>>> # Example of target with class indices >>> loss = nn. In short, CrossEntropyLoss . Computes the cross-entropy loss between true labels and predicted labels.The dice loss should as least reduce the spatial dimensions, which is different from cross entropy loss, thus here the none option cannot be used. 3、NLLLoss的结果就是把上面的 . Some are using the term Softmax-Loss, whereas .
What Is Cross Entropy Loss? A Tutorial With Code
We implement cross-entropy loss in Python and optimize it using gradient descent for a sample classification task. sum: the output will be summed. Particularly, you will learn: How to train a logistic . 2、然后将Softmax之后的结果取log,将乘法改成加法减少计算量,同时保障函数的单调性 。. For instance, in language modeling, cross-entropy can help measure how likely the predicted next word is compared to the words . So predicting a probability of . It is also known as log loss .State-of-the-art neural networks are vulnerable to adversarial examples; they can easily misclassify inputs that are imperceptibly different than their training and test data. The PyTorch implementations of CrossEntropyLoss and NLLLoss are slightly different in the expected input values.The categorical cross-entropy loss is exclusively used in multi-class classification tasks, where each sample belongs exactly to one of the ? classes. I would like to pass in a weight matrix of shape batch_size , C so that each sample is weighted .I’m working on a problem that requires cross entropy loss in the form of a reconstruction loss.- GeeksforGeeks. which is the same as optimizing the average cross-entropy in the sample.
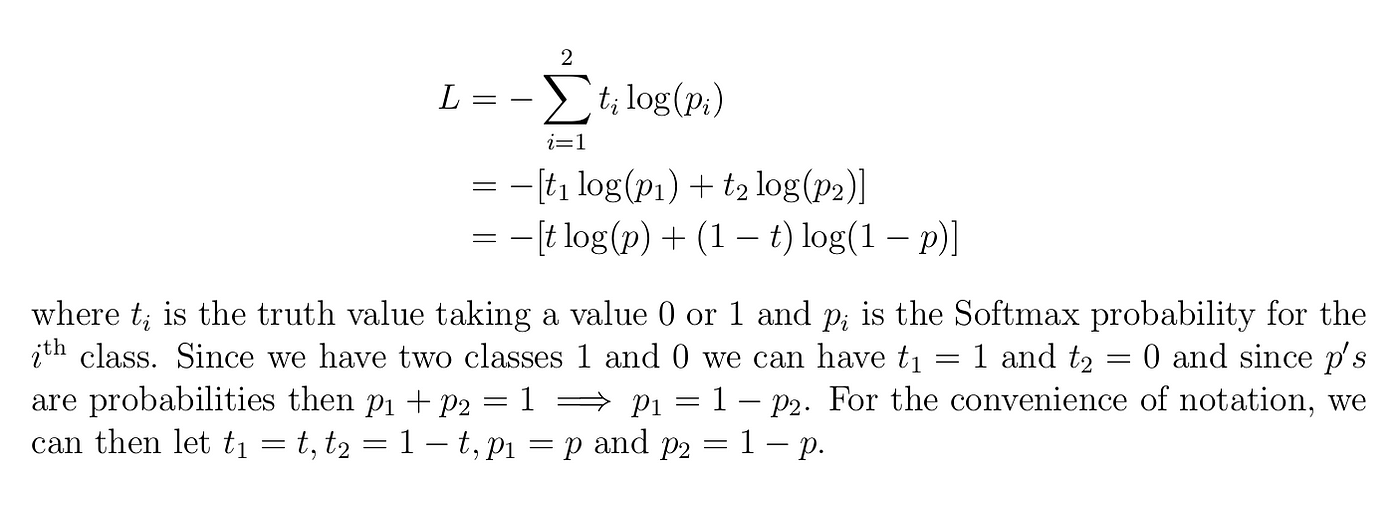
Last Updated: Jun 26, 2023.Now, consider a scenario where the true label y is 1, but your model predicts p =0.CrossEntropyLoss controls how the loss is averaged across samples (e. Binary Cross Entropy, also known as Binary Log Loss or Binary Cross-Entropy Loss, is a .Towards Data Science.BLOG Machine Learning. That is good, because we want the probabilities to be normalized.For each sample in the dataset, the cross-entropy loss reflects how well the model’s prediction matches the true label.Binary Cross Entropy/Log Loss measures the dissimilarity between the actual labels and the predicted probabilities of the data points being in the positive class. The output loss is an unformatted dlarray scalar.Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. Multi Classification Examples of Cross Entropy Loss. Softmax is combined with Cross-Entropy-Loss to calculate the loss of a model. randomseed42 randomseed42.前言cross-entropy loss function 是在机器学习中比较常见的一种损失函数。在不同的深度学习框架中,均有相关的实现。但实现的细节有很多区别。本文尝试理解下 cross-entropy 的原理,以及关于它的一些常见问题.Binary Classification Examples of Cross Entropy Loss.
Cross-Entropy Loss for Classification Tasks: Pros and Cons
August 28, 2023. In the case of Binary Cross-Entropy Loss, there are two distinct classes. It penalizes the . What Is Cross-Entropy Loss Function? Last Updated : 03 Jan, 2024. Cross entropy loss is well-suited for multi-class classification but not ideal for regression tasks (predicting continuous values).00: Perfect probabilities.Cross-entropy and negative log-likelihood are closely related mathematical formulations. The aim is to minimize the loss, i. Cross-entropy can be used to define a loss function in machine learning and optimization. There we considered quadratic loss and ended up with the equations below. In this tutorial, you’ll learn about the Cross-Entropy Loss Function in PyTorch for developing your deep-learning models. When working on a Machine Learning or a Deep Learning Problem, .
Cross Entropy Loss: Intro, Applications, Code
Overview; LogicalDevice; LogicalDeviceConfiguration; PhysicalDevice; experimental_connect_to_cluster; experimental_connect_to_host; experimental_functions_run_eagerly In fact, thanks to the properties of the exponential function, the softmax forces all elements to be x_i > 0 and the sum of all elements to add up to 1.2)=−(1⋅log(0.
Cross-entropy for classification
aᴴ ₘ is the mth neuron of the last layer (H) We’ll lightly use this story as a checkpoint. Interpretability with Binary Classification: In binary classification, since there are two classes (0 and 1) it is .FloatTensor([2.
A Simple Introduction to Cross Entropy Loss
python
Cross-Entropy 101.However, as ‘Q’ diverges from ‘P’, cross-entropy increases, indicating that ‘Q’ is a less accurate representation of the data. Towards Data Science. Each predicted probability is compared to the actual class output value (0 or 1) and a score is calculated that penalizes the probability based on the distance from the expected value.Starting to look familiar? This is precisely cross entropy, summed over all training examples: $$ -\log L(\{y^{(n)}\}, \{\hat{y}^{(n)}\}) = \sum_n \big[-\sum_i y_i \log . Cross-entropy is a commonly used loss . I would like to weight the loss for each sample in the mini-batch differently. Here, the loss is substantially higher, reflecting a substantial misalignment between the predicted probability and the true label.Practical Examples and Interpretation. Categorical Cross-Entropy: Cross .
![[DL] Cross entropy loss (log loss) for binary classification - YouTube](https://i.ytimg.com/vi/zhuuD9gckYo/maxresdefault.jpg)
Cross-entropy loss measures the difference between the predicted probabilities and the true labels of a classification task.012 when the actual observation label is 1 would be bad and result in a high loss value.In your example you are treating output [0, 0, 0, 1] as probabilities as required by the mathematical definition of cross entropy. As one can see, each element depends on the values all the remaining N_C-1 elements.

2)+(1−1)⋅log(1−0. For unformatted input data, use the ‚DataFormat‘ option.
Cross-Entropy Loss in ML
The essential part of computing the negative log-likelihood is to “sum up the correct log probabilities. The formula for cross-entropy loss in binary classification (two classes) is: Where: H ( y, p) is the cross-entropy loss. mean: the sum of the output will be divided by the number of elements in the output. A perfect model has a cross-entropy loss .Cross-entropy, also known as logarithmic loss or log loss, is a popular loss function used in machine learning to measure the performance of a classification model.For example, something like, from torch import nn weights = torch. In this article, we’ll go over its derivation and . Run this code, we will see: Then we can start to compute cross entropy loss.
Using weights in CrossEntropyLoss and BCELoss (PyTorch)
If ‘Q’ is the same as ‘P’, cross-entropy is equal to entropy.Cross-entropy loss function and logistic regression.Geschätzte Lesezeit: 4 min


empty ( 3 , dtype = torch . Improve this answer. Then we should create an input and target. Let’s dive into cross-entropy functions and discuss their applications in machine . Here batch size = 3. Anqi Mao, Mehryar Mohri, Yutao Zhong. But, what guarantees can we rely on when using cross . 1、Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。. One of the most common loss functions used for training neural networks is cross-entropy.This video discusses the Cross Entropy Loss and provides an intuitive interpretation of the loss function through a simple classification set up.Some intuitive guidelines from MachineLearningMastery post for natural log based for a mean loss: Cross-Entropy = 0.Cross-entropy loss is often simply referred to as “cross-entropy,” “logarithmic loss,” “logistic loss,” or “log loss” for short. L=0 is the first hidden layer, L=H is the last layer.First, we should import some libraries. Cross-entropy loss also known as log loss is a metric used in machine . For example, suppose we have samples with each sample indexed by =, . The true probability is the true .Cross-entropy loss function and logistic regression Cross . A Simple Introduction to Cross .Image by author.Autor: Anjali Bhardwaj
Cross-Entropy Loss Function
δ is ∂J/∂z. In this article, we will understand what Cross . Calculating the Binary Cross-Entropy: H(1,0. The true label assigned to each sample consists hence of a single integer value between 0 and ? -1. y is the true label (0 or 1).It’s widely used in tasks like binary classification, where the goal is to categorize data into two classes.For a binary classification like our example, the typical loss function is the binary cross-entropy / log loss.The reduction argument in nn.These probabilities sum to 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. smooth_nr – a small constant added to the numerator to avoid zero. loss = crossentropy(Y,targets) returns the categorical cross-entropy loss between the formatted dlarray object Y containing the predictions and the target values targets for single-label classification tasks. Cross-Entropy < 0. Loss Function: Binary Cross-Entropy / Log Loss. Run this code, we will see: We should notice: When reduction = none ,the cross entropy loss of each sample will be returned. In this work, we establish that the use of cross-entropy loss function and the low-rank features of the training data have respon-sibility for the existence of these inputs. Photo by Fatos Bytyqi on Unsplash. This technique can be implemented by adding a modulating factor to the Cross-Entropy loss. Binary Cross-Entropy, Categorical Cross-Entropy. Follow answered May 27, 2021 at 22:08.Cross - entropy loss is used when adjusting model weights during training.
Cross-entropy loss for classification tasks
Binary Cross-Entropy Loss(BCE) is a performance measure for classification models that outputs a prediction with a probability value typically between 0 and 1, and this prediction value corresponds to the likelihood of a data sample belonging to a class or category. Down weighting is a technique that reduces the influence of easy examples on the loss function, resulting in more attention being paid to hard examples.Binary Cross-Entropy: Cross-entropy as a loss function for a binary classification task. TL;DR at the end. But notably, a .Bewertungen: 71
Loss and Loss Functions for Training Deep Learning Neural Networks
It coincides with the logistic loss applied to the outputs of a neural network, when the softmax is used.
Derivative of the Softmax Function and the Categorical Cross-Entropy Loss
Classification Loss Functions — used in classification neural networks; given an input, the neural network produces a vector of probabilities of the input belonging to various pre-set categories — can then select the category with the highest probability of belonging; Ex. Cross entropy is a loss function that can be used to quantify the difference between two probability .
- Crosstrainer Richtig Benutzen | Richtig trainieren mit dem Crosstrainer
- Create Private Package Npm : Creating and publishing private packages
- Ctc 3D Drucker Software , Umstieg auf CURA mit dem alten CTC
- Critical Illness Insurance Quotes
- Crema Pasticciera Anleitung | Pastry cream
- Csl Wireless N Repeater Reset _ CSL Wireless-N WiFi Repeater Bedienungsanleitung
- Crivit 74884 Bedienungsanleitung Pdf
- ¿Cuál Es El Downtown De Los Angeles?
- Ctm Personalberatung Gmbh , UNSERE LEISTUNGEN
- Crowddesk Namen , Im Interview mit CrowdDesk
- Cte Bei Alzheimer , Alzheimer: Symptome, Ursache, Vorbeugen
- Criminal Tattoo Deutsch : Gefängnistätowierungen: Lebensgeschichten unter der Haut
- Ctx Medizinische Abkürzung : TNM-Klassifikation