Nvidia Cuda Thread _ Cooperative Groups: Flexible CUDA Thread Programming
Di: Luke
历史上,CUDA 编程模型为线程协作提供了一个简单的方法:block 中所有线程的 barrier 原语,由 __syncthreads() 函数实现。. But from this video . Typically each thread executes the same operation on different elements of the data in parallel. The dimension of the thread block is accessible within the kernel through . Python is one of the most popular .They can be used to implement producer-consumer models using CUDA threads.0 there are Maximum . The narrator says that if you have more threads than data to be processed, it won’t be a problem, but then we have to guess when the opposite happens, .
Cooperative Groups: Flexible CUDA Thread Programming
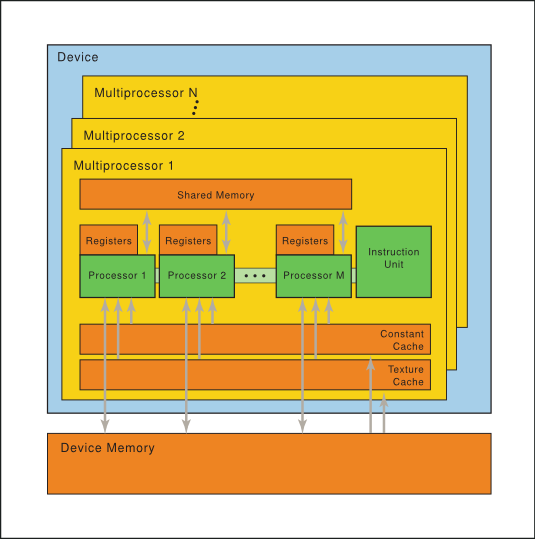
No packages published .一个GPU中通常有多个SM,每个SM上支持许多个线程并发地执行,CUDA采用单指令多线程(Single-Instruction Multiple-Thread,SIMT)来管理和执行GPU上的众多线程,并提出一个两级的线程层级结构的概念以便组织线程。由一个内核启动所产生的所有线程统称为一个线程网格,同一网格中的所有线程共享全局内存空间 .CUDA 7 introduces a ton of powerful new functionality, including a new option to use an independent default stream for every host thread, which avoids the serialization of the . I am referring the ‘global thread id’ being each unique instance of a thread within the kernel. 然而,CUDA 程序员经常需要定义和同步小于 block size 的线程组,以 . 2020Multiprocessors or Cuda Cores6.45The Compute Work Distributor will schedule a thread block (CTA) on a SM only if the SM has sufficient resources for the thread block (shared memory. If I use cudaThreadExit at the end .CUDA C++ Best Practices Guide.
CUDA Context and host multi-threading
nvidia
1 ( older ) – Last updated April 3, 2024 – Send Feedback.The Multi-Process Service (MPS) is an alternative, binary-compatible implementation of the CUDA Application Programming Interface (API). The __ffs() primitive returns the 1-based index of the lowest set bit, so subtract 1 to get a 0-based index.Empfohlen auf der Grundlage der beliebten • Feedback
Flexible CUDA Thread Programming
The NVIDIA® CUDA® Toolkit provides a development environment for creating high-performance, GPU-accelerated applications. cuda cryptonight xmrig randomx Resources.本项目为CUDA官方手册的中文翻译版,有个人翻译并添加自己的理解。主要介绍CUDA编程模型和接口 CUDA C++ 通过允许程序员定义称为kernel的 C++ 函数来扩展 C++,当调用内核时,由 N 个不同的 CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。 使用 声明说明符定义内核,并使用新的 执行 .0, this “temp” array will be available per “Context” and hence all threads . The table 14 that you mentioned specifies that for CUDA capability 2. If you are not sure what you are doing, just don’t run cudaThreadExit () in anywhere in your code.0, x, y); Grid-stride loops are a great way to make your CUDA kernels flexible, scalable, debuggable, and even portable.In the previous post, I looked at how global memory accesses by a group of threads can be coalesced into a single transaction, and how alignment and stride affect coalescing for various generations of CUDA hardware. Contexts and Streams are NVIDIA Driver related. The code we wish to optimize is a transpose of a matrix of single precision values that operates out-of-place, i. If you need run several kernels, don’t run cudaThreadExit () in between.
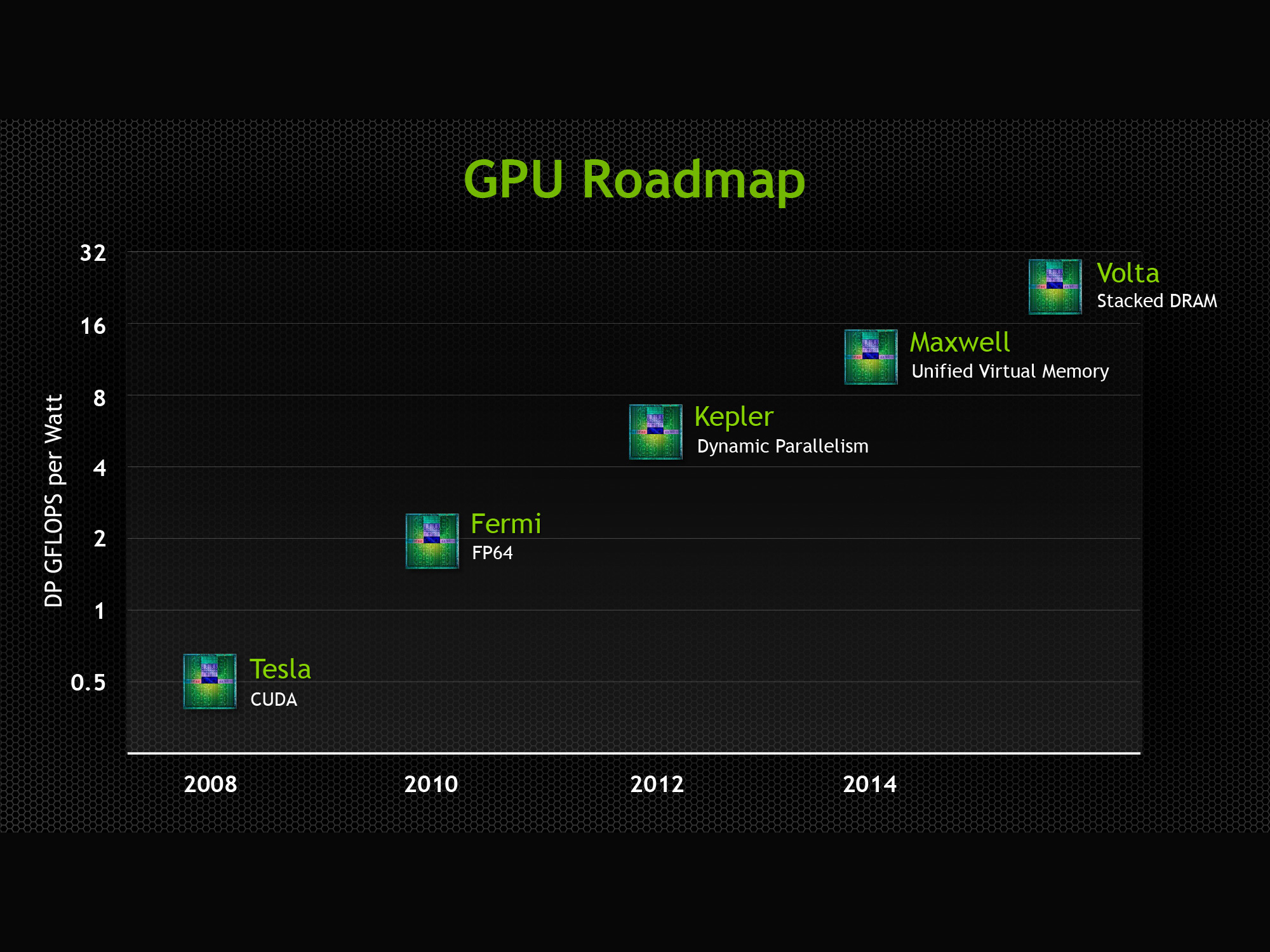
NVIDIA Ampere GPU Architecture Tuning Guide
webpage: Blog Efficient CUDA Debugging: Memory Initialization and Thread Synchronization with NVIDIA Compute Sanitizer.The NVIDIA® CUDA® Toolkit provides a comprehensive development environment for C and C++ developers building GPU-accelerated applications. __device__ int temp[CONFIGURED_MAX]; With CUDA 4. Task graph acceleration. The programming guide to using the CUDA Toolkit to obtain the best performance from NVIDIA GPUs. hemi::cudaLaunch(saxpy, 1<<20, 2. Each block can be 1D, 2D or 3D in shape, and can consist of over 512 threads on current hardware.Constant memory allocation and initialization - NVIDIA . A task graph consists of a . Cuda Cores are also called Stream Processors (SP).We can launch the kernel using this code, which generates a kernel launch when compiled for CUDA, or a function call when compiled for the CPU.Learn the syntax and semantics of the PTX ISA, a low-level parallel thread execution virtual machine and instruction set architecture. 151 forks Report repository Releases 23.That means if GPU memory is allocated in one thread a second thread does not have access to this GPU memory space. As for launching kernels at the same time this is not a problem from a CUDA point of view.5GB memory and 16 SMs. Installing NVIDIA . 338 stars Watchers.x device has a maximum of 1536 resident threads per multiprocessor. With it, you can develop, optimize, and deploy your applications on GPU-accelerated embedded systems, desktop workstations, enterprise data centers, cloud-based platforms, and supercomputers. However the end point is similar (a limit to the number of threads and blocks).0 license Activity. Document Structure.) Then elect a leader.
CUDA Refresher: The CUDA Programming Model
CUDA architecture limits the numbers of threads per block (1024 threads per block limit).The NVIDIA Ampere GPU architecture retains and extends the same CUDA programming model provided by previous NVIDIA GPU architectures such as Turing and .The maximum local memory size (512KB for cc2. However sometimes the application might need to leverage certain GPU features like: And warp size is 32.1 Latest Mar 23, 2024 + 22 releases Packages 0. total 6144 threads in GPU.
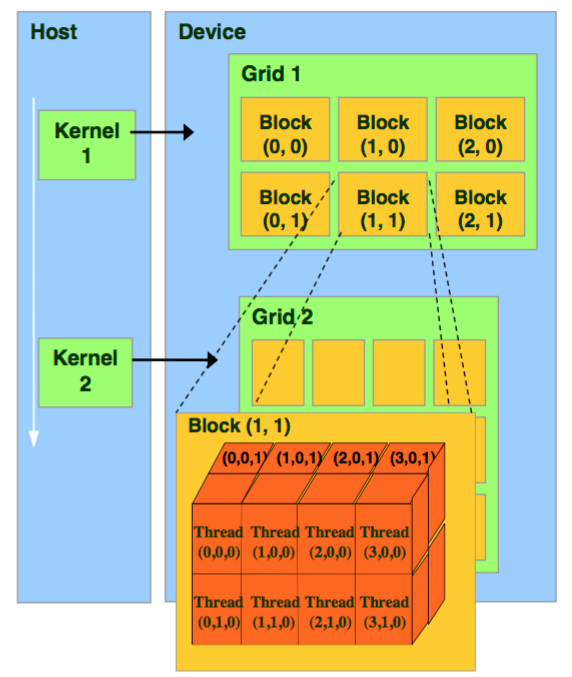
However, striding through global memory is . It will be clear to a CUDA programmer. Mai 2020Thread vs Stream what is the difference?2.Hello, I am new to CUDA and trying to wrap my head around calculating the ‘global thread id’ What I mean by this is the following: Say we have a grid of (2,2,1) and a blocks of (16,16,1) this will generate 1024 threads with the kernel invocation. The MPS runtime architecture is designed to transparently enable co-operative multi-process CUDA applications, typically MPI jobs, to utilize Hyper-Q capabilities on the latest NVIDIA (Kepler and later) GPUs. Juni 2021nvidia – Understanding CUDA grid dimensions, block dimensions and .
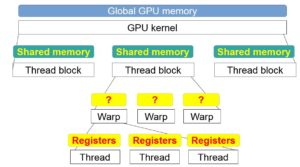
For recent versions of CUDA hardware, misaligned data accesses are not a big issue.0, CUDA Runtime Version = 8.Usually there are not huge differences in performance for a code between, say, a choice of 128 threads per block and a choice of 256 threads per block. 39 watching Forks.With Independent Thread Scheduling, the GPU maintains execution state per thread, including a program counter and call stack, and can yield execution at a per . The number of threads that .This works with CUDA 8, but is deprecated starting with CUDA 9. 2010Weitere Ergebnisse anzeigen In general you want to size your blocks/grid to match your data and simultaneously maximize occupancy, that is, how many threads are .Matrix Transpose. Threads can access data in shared memory loaded from global .Number of threads per multiprocessor=2048.CUDA Runtime API :: CUDA Toolkit Documentation. As a consequence, multiple host threads are required to execute device code on multiple devices.0, NumDevs = 1, Device0 = Tesla C2075 Result = PASS. CUDA Runtime API ( PDF ) – v12.NVIDIA’s CUDA Python provides a driver and runtime API for existing toolkits and libraries to simplify GPU-based accelerated processing. Every context has a default stream.How does the Thread Block Cluster of the Nvidia H100 work concurrently?5.The thread / block layout is described in detail in the CUDA programming guide. Contributors 5. the input and output are separate arrays in memory.Hi, I thought it must be possible to reuse a floating CUDA context in a host-multithreading application several times ? I had a look at the example “threadMigration” of CUDA2. cudaError_t cudaSetDevice(int device) After this call all CUDA API commands go to the current set device until cudaSetDevice() is called again with a different device ID. deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8. Shared memory is relatively fast .synccheck: Thread synchronization hazard detection. Sorted by: 111. In addition to these tools, Compute Sanitizer capabilities include: An API to enable the creation of sanitizing .
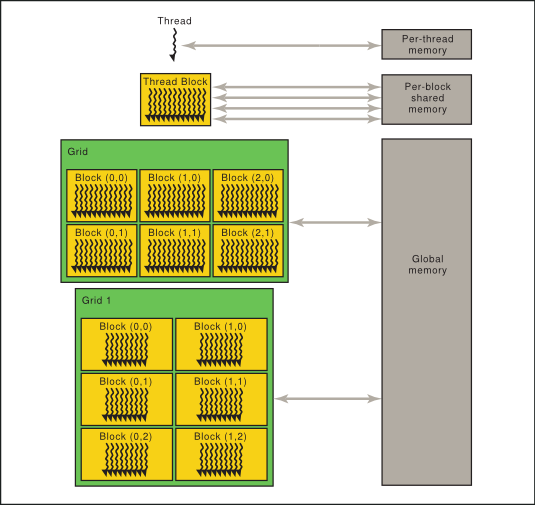
Cooperative Groups extends the CUDA programming model to provide flexible, dynamic grouping of cooperating threads.As described in the NVIDIA CUDA Programming Guide (NVIDIA 2007), the shared memory exploited by this scan algorithm is made up of multiple banks.As I understand, in earlier CUDA releases – If you declare a GPU array like below, each CPU thread working on the SAME DEVICE will inherit a separate context and hence a separate physical copy of the array.
Fehlen:
thread6cuda – How many threads can a Nvidia GPU launch?28.weigo August 22, 2007, 9:50am 2. int leader = __ffs(active .Subscribe to NVIDIA CUDA SDK Updates.I can take as example the nVidia video of “First CUDA program” and the infamous and ever repeated vector add, on which all the 1024 elements can be assigned to their own thread.
CUDA FAQ
Also, pursuant to previous discussions in this thread, the modern design technique for a persistent kernel is to use cuda cooperative groups in a cooperative kernel launch, instead of the calculations and considerations as they are laid out in comments 7 and 8 above.
CPU threads and CUDA
The runtime API has mechanisms to ensure that a multithreaded application will always pick up the same CUDA context, per device. A stream is an in-order channel of GPU operations.As a strong supporter of open standards, Jim Keller tweeted that Nvidia should have used the Ethernet protocol chip-to-chip connectivity in Blackwell-based . Historically, the CUDA programming .
NVIDIA CUDA Tutorial 4: Threads, Thread Blocks and Grids
Question about threads per block and warps per SM
total 6 blocks.For the latest compatibility software versions of the OS, CUDA, the CUDA driver, and the NVIDIA hardware, refer to the cuDNN Support Matrix. Table of Contents.Cooperative Groups Fundamentals
CUDA C++ Best Practices Guide
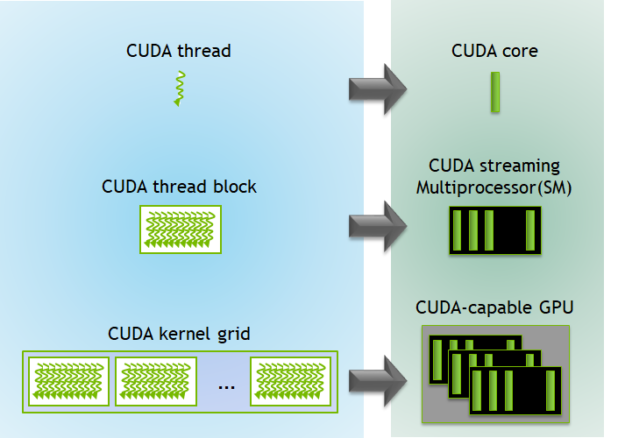
Threads within a warp are called lanes; the simplest way to elect a leader is to use the active lane with the lowest number. When multiple threads in the same warp access the same bank, a bank conflict occurs unless all threads of the warp access the same address within the same 32-bit word.NVIDIA CUDA plugin for XMRig miner Topics.Shared memory is allocated per thread block, so all threads in the block have access to the same shared memory. In particular, chapter 4 states: The CUDA architecture is built ar. When writing compute shaders, it’s often necessary to communicate values between threads.What is the relationship between a CUDA core, a streaming multiprocessor and the CUDA model of blocks and threads? What gets mapped to what and what is . Get notified of new releases, bug fixes, critical security updates, and more. The CUDA runtime API is thread-safe, which means it maintains per-thread state . The data is split up into a 1D,2D or 3D grid of blocks. When you launch a CUDA kernel, you define a total number of threads that will execute the kernel. Barriers also provide mechanisms to synchronize CUDA threads at different granularities, not just warp or block level.The GPU hardware has NO knowledge about a “Stream”, It only knows about spawning threads and executing kernels.The short answer is: don’t run cudaThreadExit () You should only use cudaThreadExit () when you decide you are done with the thread. Also, any CUDA resources created .Beste Antwort · 75For the GTX 970 there are 13 Streaming Multiprocessors (SM) with 128 Cuda Cores each. From the CUDA programming guide: Several host threads can execute device code on the same device, but by design, a host thread can execute device code on only one device. Cooperative Groups扩展了CUDA编程模型,可以灵活、动态地对线程进行分组。. 6144/1024=6 ,ie. For simplicity of presentation, we’ll consider only square matrices whose dimensions are integral multiples of 32 on a side. This is typically done through shared memory.The CUDA runtime API is state-based, and threads execute cudaSetDevice() to set the current GPU. This made me think that something like the following should be possible (very simplistic): host thread: create a context ‘ctx’ cuCtxCreate, . CUDA uses many threads to simultaneously do the work that would. 2022[HOW TO] Setup CUDA Compiler on Code::Blocks Author not me . Mai 2020Weitere Ergebnisse anzeigenThis tute we’ll delve into the crux of CUDA programming, threads, thread blocks and the grid. It is not correct that the GPU . For performance reasons it might be important to know . Scalable Data-Parallel Computing using GPUs.
However this total number of threads (the grid) is defined hierarchically – using two numbers, the first specifying blocks per .If you’ve never done any CUDA programming at all, that may not be very clear.CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES – . CUDA task graphs provide a more efficient model for submitting work to the GPU. Kepler GPUs introduced shuffle intrinsics, which enable threads of a warp to directly read each other’s registers, avoiding memory access and synchronization. So, 3*2048=6144.
Tag: CUDA
x and higher) GPU memory/ (#of SMs)/ (max threads per SM) Clearly, the first limit is not the issue.CUDA broadly follows the data-parallel model of computation.
Multiple Kernel calls are automatically put in a queue and executed sequentially.Efficient CUDA Debugging: Memory Initialization and Thread Synchronization with NVIDIA Compute Sanitizer NVIDIA Compute Sanitizer is a powerful tool that can save you time and effort while improving the reliability and performance of your CUDA applications. PTX ISA Version 8.
CUDA 编程手册系列第二章: CUDA 编程模型概述
webpage: Session Accelerating CUDA . Readme License. I assume you have a standard GTX580, which has 1.
- Number 1 Tennis Players : WTA Rankings History
- Öbb Nachtzug Wien Berlin , Nachtzug von Berlin nach Wien
- Nussallergie Rezepte | Nussallergie Erfahrung & Tipps
- Nürnberger Kündigung Email | GARANTA KFZ-Versicherung Adresse Hotline und E-Mail
- O Que Fazer Quando O Gato Tem Felv?
- Nummernschild Reservieren Bochum
- Nvidia Geforce Experience Games
- Nur Ein Herzschlag Entfernt Songtext
- Nürnberger Beteiligungs Ag Dividendenzahlung
- Öamtc Übungsplatz Wien : Freiwillige Radfahrprüfung
- Nvidia Systemsteuerung Windows 11 Öffnen
- O Que Causa Excesso De Remela Nos Olhos?