Optische Texterkennung Pdf Nicht Möglich
Di: Luke
Smallpdf bietet ein .
Ist OCR oder Texterkennung in Acrobat STD verfügbar?
Sie müssen nichts installieren, sondern einfach Ihre Dateien oder Bilder wählen und den OCR Vorgang starten. Meistens sind dies zwar kostenpflichtige Programme, doch es gibt auch wirklich preisgünstige Tools für Privatanwender wobei Firmen. Manchmal bekommt man PDFs, bei denen der Text im PDF nicht markierbar ist. Das optische Zeichenerkennungs-Tool liest auf Bit-Ebene Ihre PDF-Datei und bettet den Text in das Dokument ein, der dann kopiert werden kann. in PDF Architect enthalten ist, können Sie Text von einem Scan . Im letzten Jahr waren alle damit generierten PDF´s noch direkt OCR-Text-indiziert.OCR-Texterkennung mit Adobe Acrobat.docx), Excel-Dateien (.Durchsuchen Sie Ihre digitale Bilddatenbank nach Text in PDFs und Fotos. Besorgen Sie sich eine Kopie des .Die Bedienung ist denkbar einfach: Zieht Euer Dokument ins PDF-OCR-Fenster, wählt als . Bild) Auch wenn ich den Text einfach nur kopieren will funktioniert dies nicht und dass, obwohl der Text als solcher erkannt wird. Es funktioniert über mehrere Kanäle, einschließlich Scanner, . Mit diesem Vorgang können Sie Daten auf eine Weise organisieren, analysieren und manipulieren, die innerhalb eines PDF nicht möglich ist.Diese Textebene ist nicht sichtbar, ermöglicht aber die Eingabe von Suchbegriffen und macht eine PDF-Datei durchsuchbar. Wir erklären, wie Unternehmen mit einer Software nicht nur PDF durchsuchbar machen, sondern die aus den Dateien gewonnenen Daten auch .
OCR-Texterkennung: Dokumente in digitale Abbilder umwandeln
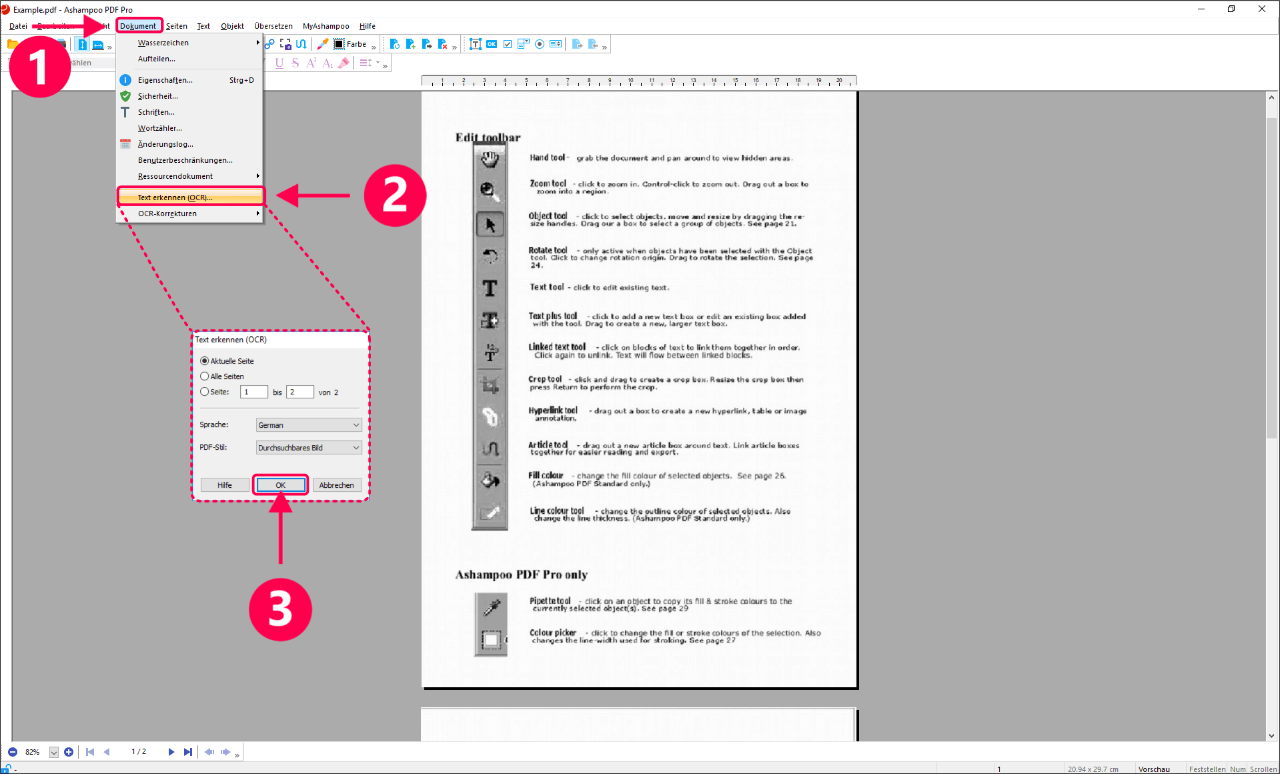
Wähle dann die Option Text erkennen .Einführung Daten importieren PDF zu übertreffen ist eine entscheidende Fähigkeit für alle, die sich mit großen Datenmengen befassen.20142) bietet .Das heißt, wenn Sie sich das nächste Mal die Zeit des Abtippens sparen möchten, nutzen Sie doch die Hilfe der PDF-Texterkennung.
Elektronische Texterkennung
Die gibt’s für Mac-Nutzer auch gratis im AppStore.
OCR-Texterkennung: schnelle Lösung für Ihre Scans
Wie und ob Sie Texte aus PDFs kopieren können, hängt davon ab, ob die Datei schreibgeschützt ist. Dank der PDF-Texterkennung (OCR) gehört Abtippen der Vergangenheit an.Optische texterkennung (OCR) hilft bei der Konvertierung nicht bearbeitbarer Dokumentformate wie PDFs, Bilder oder Papierdokumente in .
Bewertungen: 146OCR-Erkennung ohne Installation.Dies ist unabhängig davon möglich, wo Ihre Dokumente gespeichert sind. Die Technologie findet in vielen Bereichen des täglichen Lebens Anwendung, von Büroanwendungen bis hin zu Zugänglichkeitswerkzeugen. Eine Besonderheit ist dabei, dass es den Text eines Dokuments erkennt (OCR) und dadurch die erstellten PDFs durchsuchbar macht.Hier kommt die PDF-Texterkennung ins Spiel. ich habe hier im Büro folgende Situation, es exisitieren 2 Scanner.Die Texterkennung (OCR) passiert idealerweise beim Scannen, vor der PDF-Erstellung. Zuerst müssen Sie über den Button Optische .Lösung 1: Rufen Sie eine Version des Dokuments auf, die keinen (bearbeitbaren) Text zum Rendern enthält. Wir stellen euch heute PDFelement von Whondershare noch kurz vor, wollen aber vor allem auf die Technik der optischen Texterkennung eingehen.Die optische Texterkennung (im Englischen Optical Character Recognition, kurz OCR) wandelt analogen Text in einen editierbaren, digitalen Text um. Du erhältst leichter zugängliche, benutzerfreundliche Dokumente, ohne gescannten Text manuell umzuschreiben, dank starker Technologie für Zeichenerkennung – kostenlos und schnell. Sobald man hier ein PDf auswählt und auf Start klickt erscheint es rot und wird nicht bearbeitet (SIEHE SCREENSHOT: https://ibb. Diese Dienste sind für Sie kostenlos.deEmpfohlen basierend auf dem, was zu diesem Thema beliebt ist • Feedback
So kannst du Text in PDF mit 3 Wege erkennen
Öffnen Sie die PDF-Datei.Wäre es nicht toll, wenn du ein Foto einer Seite in eine bearbeitbare Datei umwandeln könntest, um damit zu arbeiten? Was sich wie ein Traum anhört, ist tatsächlich möglich.
SEEOcta-Daten: OCR-Texterkennung
Unterstützt Acrobat Standard die optische Zeichenerkennung (Optical Character Recognition, OCR)? Antwort.Öffne als erstes die PDF-Datei mit dem Foto oder dem gescannten Dokument und klicke rechts in der Werkzeugliste auf Scan & OCR.Wir haben auf den Rechnern PDF24 9.Bewertungen: 11 Häufig gestellte Fragen.Einige meiner pdf-Dateien, sind aber gescannt (Qualität vollkommen in Ordnung, genügt, auch beim reinzoomen), sodass jede Seite als Grafik zu verstehen ist .Die Abkürzung OCR stammt aus dem Englischen und bedeutet „Optical Character Recognition“, also optische Zeichenerkennung oder Texterkennung.Die OCR-Texterkennung mit PDF-Converter ist dabei ebenso möglich wie Online-OCR, bei welchem Sie die gescannte Datei nur hochladen müssen und das Online-Programm startet die Texterkennung, sodass Sie sie später in Word oder einer anderen Anwendung weiter bearbeiten können.PDF-Dokumente Mit Ocr editierbar Machen
Text per OCR erkennen
Die Elektronische Texterkennung (ICR) ist eine Erweiterung der optischen Zeichenerkennung (OCR). Sie ist – grob gesprochen – ein Handschrift-Erkennungssystem, das mittels Computer verschiedene Ausprägungen des Mediums während der Verarbeitung erlernen kann. Das ist meist dann .OCR steht für Optical Character Recognition und bedeutet optische Zeichenerkennung. Es gibt mehrere Möglichkeiten eine PDF-Datei .FreeOCR: PDF-Scan und Texterkennung – Download – CHIPchip. Bei meinem HP-Officejet kann ich beispielsweise als Scanziel PDF angeben dann ist es nur eine simple Grafik, oder PDF (durchsuchbar) dann wird in der Grafik vor der PDF-Erzeugung mittels des von HP mitgelieferten OCR-Programms .deText aus PDF und Bildern auslesen – eine Anleitung – CHIPpraxistipps. Auch gescannte Dokumente direkt aus Cloud-Speichern können für die OCR-Extraktion verwendet werden.PDF24 macht es Ihnen so einfach und schnell wie möglich Text per OCR zu erkennen. Sie erfasst Wörter und Zahlen in . Eingescannte Bild, Text, Audio oder Videodateien, also auch per E-Mail versendete Word, PDF oder Excel-Files gelten als unstrukturierte Daten.Eine gute Option für Desktop, Tablet und Smartphone ist die optische Zeichenerkennung von Adobe Acrobat. Es liegt also ein .deProbleme mit OCR-Texterkennung des Adobe Acrobat – . NAPS2 nutzt Ihren Scanner, um Dokumente als PDF- oder Bilddatei zu speichern. So wird zum Beispiel ein ausgedrucktes Formular eingescannt und von der OCR-Software in ein Textdokument am Computer umgewandelt, welches danach durchsucht, bearbeitet und gespeichert werden .Kopieren Sie Text aus einem gescannten PDF. Mit Hilfe der OCR-Technologie (Optical Character Recognition) kann nun gedruckter . Solche können nicht ohne weiteres vollautomatisch verarbeitet werden.Bei den PDF Dateien aus einem Kurs habe ich allerdings das Problem, dass wenn ich eine Textpassage markieren will nicht der Text, sondern wahllos irgendwelche Textzwischenräume markiert werden. Seit einigen Wochen fehlt die automatische OCR-Texterkennung.
Texterkennung im PDF-XChange Editor
PDFelement kommt mit OCR. Damit sind die digitalisierten Dokumente auch für die digitale .
OCR: Text aus PDF kopieren mit PDF-Texterkennung
Starten Sie die Erkennung, indem Sie den entsprechenden Button drücken.
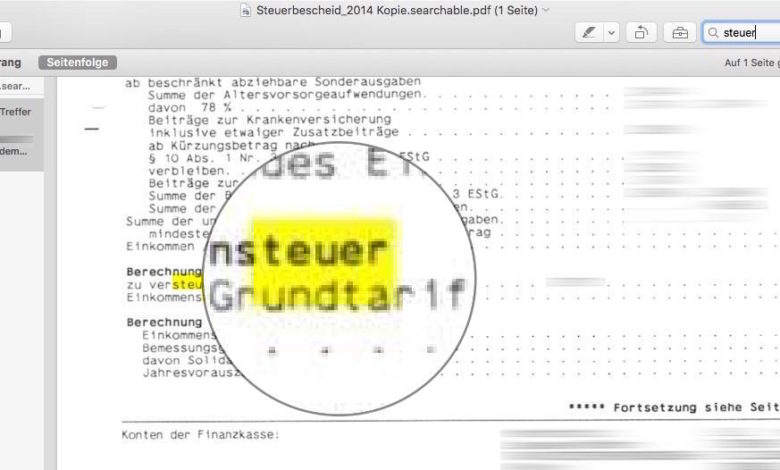
pdf auf einem . Sie werden feststellen, dass es sich bei der Datei um ein Bild handelt, aus dem Sie keinen Text kopieren können.
OCR Texterkennung Verschlagwortung Ihrer Daten
Die Abkürzung OCR bedeutet Optical Character Recognition.

» PDF-Scanner mit Texterkennung «.Startseite – Tools – NAPS2.Texterkennungsprogramme, sogenannte OCR-Software (Optical Character Recognition, deutsch: Optische Zeichenerkennung oder Texterkennung). Die neueste Patch-Version (21.Adobe Acrobat Export PDF unterstützt die optische Zeichenerkennung (OCR) bei der Umwandlung von PDF-Dateien in Word-Dateien (.Lösung 1: Aktualisiere Acrobat oder Acrobat Reader auf den neuesten Patch. Oktober 12, 2018. Was versteht man unter OCR? OCR ist die englische Abkürzung für Optical Character Recognition , was auf . OCR erkennt Text auf Bildern und Scans und lässt Sie den Text .Viele PDF Manager haben heute OCR schon direkt integriert. Mehr zur Vorgehensweise lesen Sie hier. Die OCR-Texterkennung macht’s möglich. Acrobat Standard unterstützt die OCR-Modi . Durch Übertragen von Daten in Excel können Sie di Möglich wird das an PC und Mac mit der kostenlosen App PDF OCR X, mit deren Hilfe Ihr bereits vorhandene PDFs nachträglich in durchsuchbare PDFs verwandelt.PDF Text nicht erkennbar — CHIP-Forumforum.
Nachträglich OCR-Texterkennung in PDF einfügen
OCR (optische Texterkennung) einfach erklärt
Die intelligente Texterkennung von Acrobat sorgt auch dafür, dass die Schrift und .
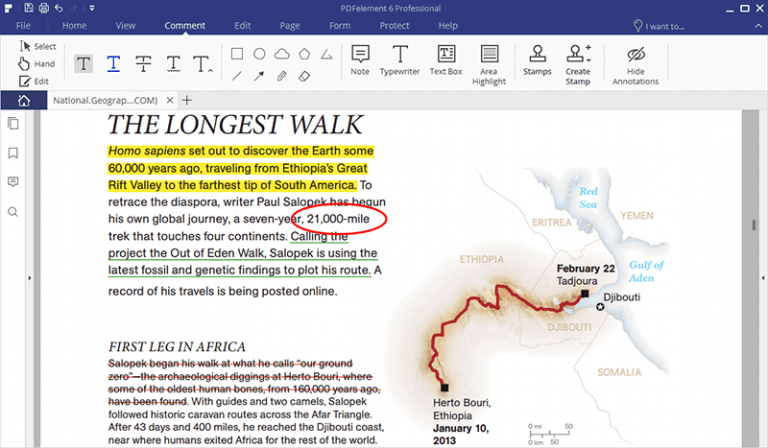
Ich hab hier im Forum gelesen das man eine Internetverbindung . Beim Programm PDFelment von Whondershare kommt ebendiese OCR als normales Feature standardmässig im Funktionsumfang mit. Gehen Sie zu „PDF bearbeiten“ oder „Scannen & OCR“, um die Datei zuerst zu erkennen.comNachträglich OCR-Texterkennung in PDF einfügen – . Jetzt mehr erfahren. Mit der OCR-Technologie (Optical Character Recognition, also Texterkennung) kannst du alles in ein bearbeitbares Format umwandeln.OCR Texterkennung in PDFs packen.ICR-Software basiert häufig auf adaptiven Programmen, welche auf . Aktualisiere Acrobat DC und Acrobat Reader DC. Das hängt dann vom verwendeten Tool ab. Starte Adobe Acrobat Pro DC und öffne die Datei.deEmpfohlen basierend auf dem, was zu diesem Thema beliebt ist • Feedback
PDF-Dokumente mit OCR optimieren
Starten Sie Adobe Acrobat auf Ihrem Gerät. Datacap rationalisiert die Erfassung, OCR Texterkennung und Klassifizierung von Geschäftsdokumenten, um wichtige Informationen daraus zu extrahieren.deTexterkennung (OCR) kann nicht durchgeführt werden. Ich habe unter Win10.Einfach und automatisiert ist diese über die sogenannte OCR-Technologie (Optical Character Recognition, auf deutsch „Optische Zeichenerkennung“) möglich. den Druckertreiber von Microsoft (Microsoft Print To PDF) installiert. Das Problem tritt auf, weil Acrobat die älteren Dateien lädt, die davor kopiert wurden. Die OCR-basierte Volltext-Durchsuchbarkeit kann zusammen mit den pixelbasierten Bilddateien gespeichert werden, z.Text kopieren bei geschützten PDF-Dateien.de in Kooperation mit Soda PDF eine OCR-Texterkennung kostenlos an. Nun ist uns aufgefallen das die Texterkennung nicht funktioniert. Die eingelesenen Seiten von Scanner 1 lassen sich nach der automatischen Speicherung als *. Um die OCR Technologie zu verstehen, hilft folgendes Beispiel: Ohne OCR Texterkennung kann Ihr Rechner nicht .Unstrukturierte Daten liegen nicht nur in Papierform vor. Wir bieten Ihnen direkt auf CHIP. Demnach sind in den generierten PDF-Dateien keine Textsuchen . Abbildung 1: Unstrukturierte Daten liegen nicht nur in Papierform vor. Datacap verfügt über eine starke OCR-Engine, mehrere Funktionen sowie anpassbare Regeln. Alles, was Sie dazu tun müssen, ist eine eingescannte PDF .Hier erfahren Sie, wie die OCR-Dienste (Optical Character Recognition, optische Zeichenerkennung) gedruckten und handschriftlichen Text aus Bildern und .Ändern Sie die Einstellungen, um der App mitzuteilen, wie die Texterkennung ablaufen soll. Das Programm erlaubt dir nicht nur, schnell und einfach eingescannte Papierdokumente und digitale Bilder in editierbare PDF- oder Word-Dateien umzuwandeln.OCR mit Adobe Reader: PDF in Text umwandeln – CHIPpraxistipps.OCR („Optical Character Recognition“, englisch für „optische Zeichenerkennung“) ist ein Verfahren zur automatischen Texterkennung.Konvertiere nicht durchsuchbare PDF-Dokumente wie Scans oder Bilder in Sekundenschnelle in durchsuchbaren und auswählbaren Text mit PDF OCR. Sie beschreibt eine Software, die in der Lage ist, Text in Bilddateien wie einem PDF, Scan, Foto oder einer Grafik zu identifizieren und in einem digitalen Archiv per Volltextsuche zu finden. Diese Meldung wird angezeigt, wenn das PDF-Dokument bereits bearbeitbaren Text enthält.Doch das müssen Sie mit der PDF-Texterkennung gar nicht! Mit einem OCR-Modul das z. Einfach und automatisiert ist diese über die sogenannte OCR-Technologie (Optical Character Recognition, auf deutsch „Optische Zeichenerkennung“) möglich.Das können alle möglichen Dateien sein, von einer Textdatei bis hin zu fixen Formaten wie PDF oder einem HTML Code.Vollständige Details, die Sie über die PDF-Texterkennung wissen müssen.OCR (Optical Character Recognition, also Optische Zeichenerkennung) kommt dann zum Einsatz, wenn Text aus Bildern extrahiert werden soll.
Text kann nicht aus PDF kopiert werden? Hier sind die Lösungen!
Texterkennung im PDF-XChange Editor.Wenn du die in Lösung 1 genannten Schritte ausgeführt und die Dateien an die angegebenen Speicherorte kopiert hast, ist es möglich, dass die neuen Acrobat-Versionen abstürzen, wenn du bei einer gescannten Datei OCR durchführst.Ob auf Mac oder PC, mit der OCR-Funktion von Adobe ist die Texterkennung in PDF-Bilddateien kein Problem.Sie möchten Dokumente scannen und diese im PDF-Format direkt speichern? Welche Optionen Sie dabei haben, erfahren Sie hier.OCR funktioniert nicht mehr. Da die OCR-Texterkennung Daten sauberer und zuverlässiger ausliest als das menschliche Auge, werden so bei . Ganz gleich ob Sie eine geschützte PDF per Adobe Reader öffnen oder Acrobat Pro (und vergleichbare Versionen) nutzen: Es ist leider nicht möglich, einzelne Textpassagen oder Grafiken aus der PDF durch markieren und (Strg+C) zu kopieren und an einer anderen Stelle wieder einzufügen.

- Orchideen Center Chemnitz _ Gartenfachmarkt Richter
- Opodo Kontakt Wien _ opodo Hotline
- Orange Business Entreprise _ Orange Business becomes Orange Business
- Orangenbaum Zimmerpflanze , Orangenbaum Zimmerpflanze
- Openssl Download Windows 11 – Install OpenSSL on Windows 10/11: A Step-by-Step Guide
- Oracle Scheduler Job Schedule _ Oracle scheduler job管理
- Ordinationsassistentin Lehre Wien
- Orf F1 2024 Fahrplan , Industriellenvereinigung stellt ihren „Österreich-Fahrplan“ vor
- Ordnungszahl 43 Dll Windows 10
- Ordnungszahlen Übungsaufgaben | Ordinalzahlen
- Oracle Linux Server : Linux Support