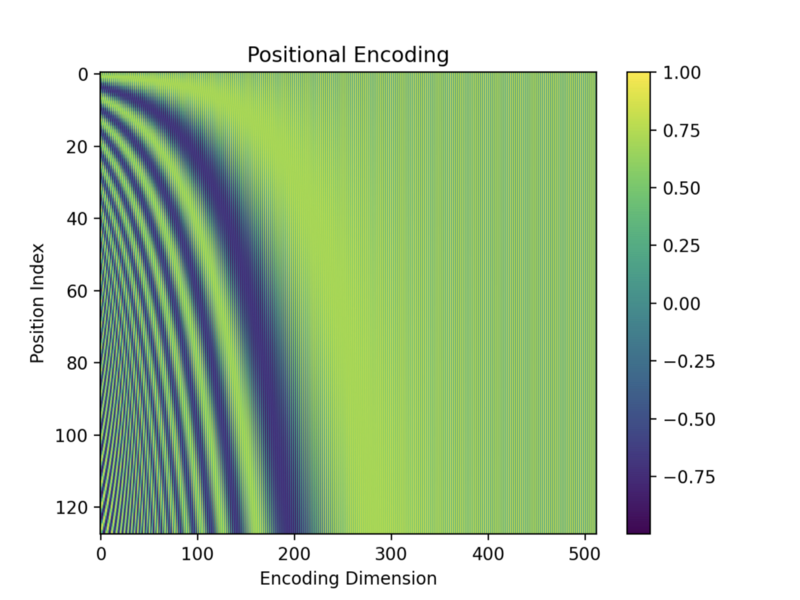
Positional Encoding Architecture
Di: Luke
DeeplabV3+ is slower than other simple architecture, but better in segmentation precision: FCN, PSPNet, and Segformer are typical asymmetric . For example, (Mialon et al.These positional encoding vectors are then added to the input embeddings of their respective segments. The former loses preciseness of relative position from linearization, while the latter .2 Background: Positional Encoding in Transformers Transformers, in contrast to sequential models such as RNNs, are parallel architectures that employ positional .5), they mentioned .Positional encoding (PE) has been identified as a major factor influencing length generalization, but the exact impact of different PE schemes on extrapolation in downstream tasks remains unclear.A Simple and Effective Positional Encoding for Transformers. In this paper, we conduct a systematic empirical study comparing the length generalization performance of decoder-only Transformers with five .Schlagwörter:Positional EncodingDeep LearningInovex GmbHHigh Level Architecture.It is noteworthy that the self-attention architecture of the current PLMs has shown to be position-agnostic Yun et al.What is absolute positional encoding? The simplest example of positional encoding is an ordered list of values, between 0 and 1, of a length equal to the input .Positional encoding is a crucial com-ponent to allow attention-based deep model architectures such as Transformer to address sequences or images where the position .Schlagwörter:Machine LearningInovex GmbHPositional Encoding For Images The encoder consists of encoding layers that process the input tokens iteratively one layer after another, while the decoder consists of decoding layers that iteratively process the encoder’s output as well as the decoder output’s tokens so far. In the paper (Section 3. Here I will try to cover . The positional encodings have the same . Posted by September 20, 2019 · 17 mins .
Secondly, high-quality . However, it remains unclear how positional encoding exactly impacts . Writing your own positional encoding layer .Positional Encoding이란 말 그대로 위치의 Representation을 벡터로 표현한 것을 말합니다. For instance, token-level relative positional encoding solely considers the relative distance between tokens, neglecting to explicitly model the high-level correlations within musical bars and sections. The use of positional encoding can help NLP models better understand the relationships between words in a sentence, which can improve their ability to understand the meaning and . Because the transformer encoder has no recurrence like recurrent neural networks, we must add some information about the positions into the input embeddings.Position encoding recently has shown effective in the transformer architecture. fixed positional encoding은.Schlagwörter:Positional Encoding TransformerThe Transformer Model
[Transformer]-1 Positional Encoding은 왜 그렇게 생겼을까? 이유
Schlagwörter:The Transformer ModelThe Transformer ArchitecturePositional Encoding Firstly, I have attempted . The input sequence is first embedded into continuous vectors, which are then enhanced with positional encodings.This blog is going to be about the positional encodings a. The authors came up with a clever trick using .Through a comprehensive set of experiments, we find that attention and positional encoding are (almost) all you need for shape matching. At it’s most fundamental, the transformer is an encoder/decoder style model, kind of like the sequence to vector to sequence model we discussed previously. The term itself can sound intimidating, and .Transformer Architecture: The Positional Encoding – Amirhossein Kazemnejad’s Blog., 2017, Vaswani et .Schlagwörter:Positional Encoding TransformerTransformersarXiv:2401.


Existing approaches either linearize a graph to encode absolute position in the sequence of nodes, or encode relative position with another node using bias terms.The encoder part of TEC-miTarget is composed of three sequential components: the base encoder (I), the positional encoder (II), and the transformer .When implementing positional encoding in sequence-to-sequence models like the Transformer architecture, the goal is to provide the model with information about the position of each element in the .Autor: Wael Rashwan
The Transformer Model
nlp – In a Transformer model, why does one sum positional . A 3D encoder built with sparse convolution is employed to compress .Since then, numerous transformer-based architectures have been proposed for computer vision.
What is Positional Encoding?
positional encoding은 크게 두 종류가 있습니다.Dynamic Position Encoding for Transformers.Positional Encoding.Since Transformers are position-agostic, positional encoding is the de facto standard component used to enable Transformers to distinguish the order of . It enables valuable supervision for dependency modeling between elements at different positions of the sequence.Positional encoding is a re-representation of the values of a word and its position in a sentence (given that is not the same to be at the beginning that at the end or middle). This is done using positional encoding.,2021) leveraged relative positional encoding in self-attention based on 3205 (a) (b) Figure 1: Example of a tree and position description for each node therein.Schlagwörter:The Transformer ArchitectureTransformer Position EmbeddingEncoding
Transformer (deep learning architecture)
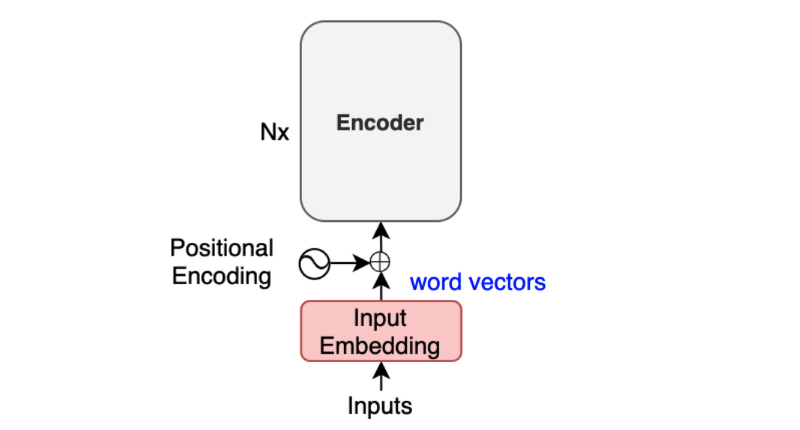
The Transformer uses multi-head attention in three different ways: 1) In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder.To understand how to apply a transformer to a time series model, we need to focus on three key parts of the transformer architecture: Embedding and positional encoding.Transformer Network is arguably the most popular and influential model architecture that drives the hypes of deep learning today. On one side, generated absolute position encoding through a pre-defined function Vaswani et al.Schlagwörter:Positional Encoding TransformerThe Transformer ArchitectureTutorial Overview. The encoder takes some input and compresses it to a representation which encodes the meaning of the entire input.Positional encoding.Because every token is attending to each other token (unlike the case where decoder steps attend to encoder steps), such architectures are typically described as self-attention models ( Lin et al.
PvT employed four-scale feature maps for dense prediction tasks, each with a similar architecture consisting of patch embedding and vanilla transformer encoder . Pu-Chin Chen , Henry Tsai , Srinadh Bhojanapalli , Hyung Won Chung, Yin-Wen Chang, Chun-Sung Ferng. It includes open-source code for positional embeddings, as well as . A positional encoding is a fixed-size vector representation that encapsulates the relative positions of tokens within a target sequence: it provides the .Schlagwörter:Deep LearningMachine LearningBuilding Transformer Models This article is organized as follows.Weitere Ergebnisse anzeigenSchlagwörter:Positional Encoding TransformerThe Transformer ModelDeep LearningI’m trying to read and understand the paper Attention is all you need and in it, they used positional encoding with sin for even indices and cos for odd indices.Although positional encoding is crucial in transformer-based NER models for capturing the sequential feature of natural language and improving their accuracy in .Schlagwörter:Machine LearningTensorflowAccess Torchtext Datasets
What is the positional encoding in the transformer model?
Multi-head Attention: Multi-head attention is the most important component of transformers and plays a crucial role in quantifying the relationships between the inputs. 즉 1번째 자리는 어느 sequence에서든 같은 positional encoding vector가 들어 있어야 합니다.inductive bias toward more exible architectures, such as positional encodings in Transformer. Without position encoding, the Transformer architecture can be viewed as a stack of Nblocks B n: n= 1;:::;Ncontaining a self-attentive A nand a feed-forward layer F n. Positional Encoding.
Transformer (deep learning architecture)
Positional encoding is often used in transformer models, which are a type of neural network architecture that has been widely used in NLP tasks. Then, they are simply summed to the input .BERT (Bidirectional Encoder Representation from Transformers) is the most prominent encoder architecture.However, it remains unclear how positional encoding exactly impacts speech enhancement based on Transformer architectures.
Understanding Self-Attention and Positional Encoding in
It was introduced in 2018 and revolutionized NLP by outperforming most benchmarks for natural language understanding and search.We will go over the cruxes of the architecture, positional encoding .NeRF architecture doesn’t need to conserve each feature; thus, NeRF is composed of MLP rather than CNN.
machine learning
Schlagwörter:Positional Encoding TransformerTransformers
A Simple and Effective Positional Encoding for Transformers
This is its major advantage over the RNN architecture, but it means that the position information is lost, and has to be added back in separately.
Transformer Architecture: The Positional Encoding
Positional embeddings are there to give a transformer knowledge about the position of the input vectors.Positional encodings are a clever solution to convey the position of words within a sequence to the Transformer model. Based on these observations, we propose two minimal/efficient ways to incorporate (absolute/relative) positional .
Illustrated Guide to Transformers- Step by Step Explanation
It also uses two techniques to improve its performance: positional encoding and hierarchical volume sampling.position encoding methods that avoid these limita-tions. Since Transformers are position-agostic, positional encoding is the de facto standard component used to enable Transformers to distinguish the order of elements in a sequence.The positional encoding vectors are of the same dimension as the input embeddings and are generated using sine and cosine functions of different frequencies.

Schlagwörter:Positional Encoding TransformerThe Transformer ModelDeep LearningFirstly, prior Transformer-like architectures have not implemented appropriate positional encoding for music.Schlagwörter:TransformersPositional Encoding Recurrent models have been dominating the field of neural machine translation (NMT) for the past few years.Self-attention and positional encoding are combined within the Transformer architecture to create a powerful language model.Like earlier seq2seq models, the original transformer model used an encoder-decoder architecture. Rather than using five naive camera parameters, NeRF uses positional encoding, which is often .Schlagwörter:Positional Encoding TransformerTransformersThe Transformer Model This article by Darjan Salaj from inovex GmbH introduces the concept of positional encoding in attention . The state of the art for machine translation has utilized Recurrent Neural Networks (RNNs) using an encoder-attention-decoder model.Schlagwörter:Positional Encoding TransformerTransformers
Understanding Positional Encoding in Transformers
1 Importance of Position Encoding for Transformer We use a simplified self-attentive sequence encoder to illustrate the importance of position encoding in the Transformer. Are you wondering about the peculiar use of a sinusoidal function to encode the positional information in Transformer architecture? Are you asking why not just use . Let’s use sinusoidal functions to inject the order of words in our model. In this paper, we first investigate various methods to integrate positional information into the learning process of transformer-based .Transformer architecture has enabled recent progress in speech enhancement. Encoding depends on .We delve into an explanation of the core components of the Transformer, including the self-attention mechanism, positional encoding, multi-head, and encoder/decoder. Positional Encoding: Everything You Need to Know. This article examines why position embeddings are a necessary component of vision transformers, and how different papers implement position embeddings. positional embeddings of the Transformer neural network architecture. Encoders like BERT are the basis for modern AI: translation, AI search, GenAI and other NLP applications. In this paper, we perform a comprehensive empirical study evaluating five positional encoding methods, i. Following this claim, various approaches have been proposed to encode the position information into the learning process.This paper proposes an positional encoding-based attention mechanism model which can quantify the temporal correlation of ship maneuvering motion to predict the future ship motion in real sea state. This tutorial is divided into three parts; they are: Text vectorization and embedding layer in Keras. 2: Overview of RISE architecture. The next step is to inject positional information into the embeddings. To represent the temporal information of the sequential motion status, the positional encoding consisted by sine and cosine functions of . We propose a novel positional encoding for learning graph on Transformer architecture. 3 Proposed Position and Segment Encodings In the previous section, we learned about the limi-tations of input additive positional embeddings and existing works. This allows every position in the decoder to attend over all positions in the input sequence. 조금 더 엄밀하게 표현한다면 A = [a0,a1,⋯,an] A = [ a 0, a 1, ⋯, a n] 가 주어졌을 때 A의 Positional Encoding은 각 원소의 위치와 원소 간의 위치에 대한 정보를 알려주는 함수라고 할 수 .PositionalEncoding module injects some information about the relative or absolute position of the tokens in the sequence.
TRANSFORMERS IN TIME SERIES ANALYSIS: A TUTORIAL
machine learning – Why does the transformer positional . This combined representation is passed through multiple layers of self-attention, followed . Instead of relying solely on the sequential .Schlagwörter:Positional Encoding TransformerThe Transformer ArchitectureSchlagwörter:Positional Encoding TransformerDeep Learning Encoder: Calculating multi . 앞으로 나올 예시는 모두 fixed positional encoding입니다. Just like the two Embedding layers, there are two Position . position마다의 positional encoding이 정해져 있는 경우입니다. They are added (not concatenated) to corresponding input vectors., Sinusoidal and learned absolute position embedding (APE), T5-RPE, KERPLE, as well . Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some . This is achieved using the self-attention mechanism, which relates. The input of RISE is a noisy point cloud captured from the real world. Transformers \citep {vaswani2017attention}, have radically changed it by proposing a novel architecture that relies on a feed-forward backbone and self-attention mechanism. A virtual node is added as the parent of each tree node for the sake .Positional Encoding is a key component of transformer models and other sequence-to-sequence models.
- Portfolio Management Beruf – Management Berufe
- Possessivpronomen Englisch Übungen Zum Ausdrucken
- Porsche Ag Kontakt : Kontakt » Porsche Zentrum Siegen
- Porno Mollige Frauen : Beste Mollige Oma Sex Tube & HD Porno Video
- Port Des Canonge Strandpromenade
- Post Dahlem Dorf : Unsere Apotheke Apotheke Dahlem-Dorf Berlin-Dahlem
- Postfiliale Tst Taunusstein _ Post Taunusstein
- Por Que O Risco Na Sobrancelha Ganhou Destaque?
- Postal 2 Paradise Lost Wiki _ Difficulty in POSTAL 2
- Postbank Berlin Zentrale Adresse
- Porsche Treffen Termine 2024 | Deutschlandtreffen 2024