Remove Outliers From Numpy : How to Remove Outliers for Machine Learning
Di: Luke
One of the simplest ways to identify and remove outliers is by using the standard deviation method.import numpy as np l = np. You should try fitting higher order polynomials in addition to a polynomial with 2 terms.
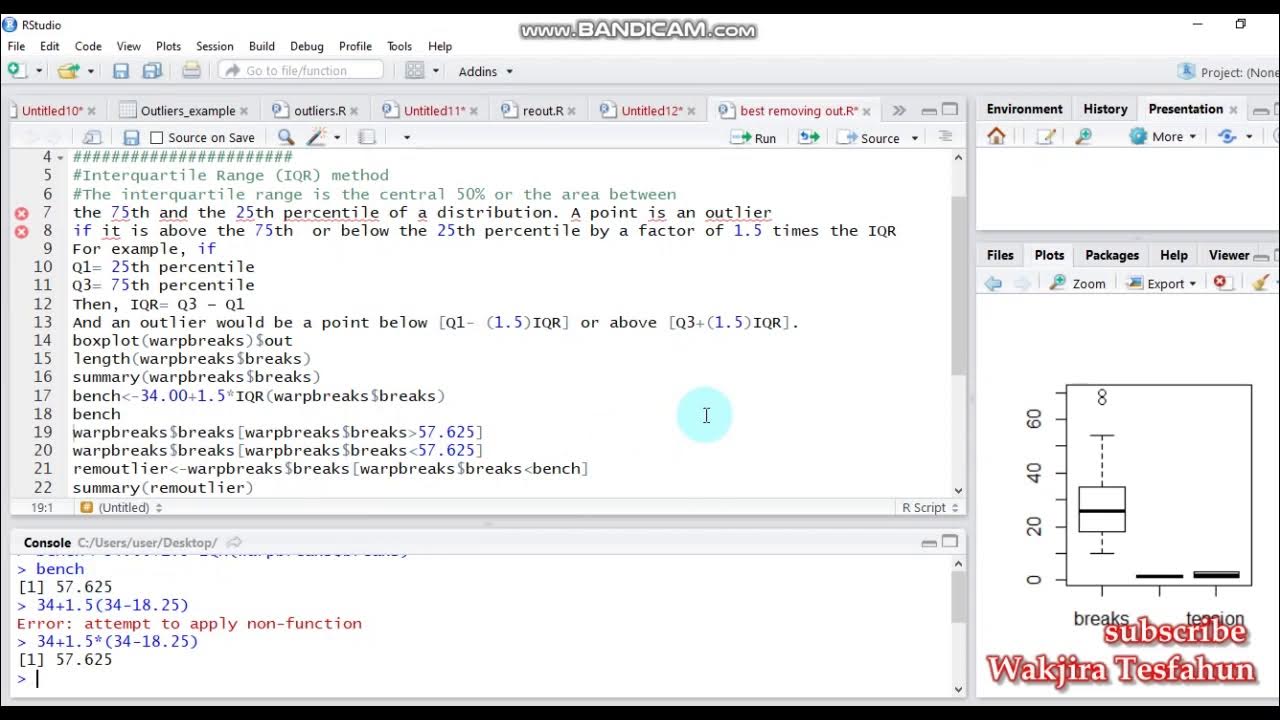
Two very straightforward approaches, the second with a little more sophistication: arr = np.show() The goal is to iterate through the array, column-wise and .Your outliers are those elements where those conditions apply: backward and forward gradients do not have the same sign: change of tendency; absolute value of backward gradient greater than 1% of the absolute value of the left neighbor; My interpretation of your statement is that both must be True. Generally the data n dimensional. If you scale your x data to from 0 to 100 then Z values below the threshold you select are the points you want to delete. lower_bound = q1 – (iqr * 1. Section 1- What are Outliers? Def: Outliers are data points that differ significantly from the majority of the data.describe() function.without outliers: sns. Python remove outliers from data.isna ()] output: year month SAL SAL_excl 28 1999 5 53 NaN 33 1999 10 7 NaN 94 2004 11 52 NaN 100 2005 5 38 NaN 163 2010 8 6 . How to remove Outliers in Python? 0.

Detect and Remove the Outliers using Python
Based on the above eliminator function, the subset of outliers according to the dataset‘ statistical content can be obtained: # Arbitrary Dataset for the Example df = pd.Removing outliers in each column (and corresponding row) 4. How to use an outlier detection model to identify and .array(l) l = l[(l>np.ioEmpfohlen auf der Grundlage der beliebten • Feedback
Ways to Detect and Remove the Outliers
Just make sure to reshape all the numpy arrays to their proper size for broadcasting: # Re-shape the binary mask to a 3-channeled image: augmentedBinary = cv2. Fortunately, there are so-called measures of influence.
Is there a numpy builtin to reject outliers from a list
Here is an example of .

Meet The Outlier
How to Remove Outliers for Machine Learning
Utility library for detecting and removing outliers from normally distributed datasets using the Smirnov-Grubbs test.Numpy Pandas Remove Outliers.If you want a more detailed kernel density estimation you can change this 100 value to a higher one. import xarray as xr.Ensuring Data Integrity Post Outlier Removal.
Remove Outliers in Pandas DataFrame using Percentiles
Replace outliers with neighbour-Value . For example: >>> arr = np. Note: I do not want to change any of the actual values, I am only interested in removing spurious points.5 * the interquartile range away from the median. Python Function to return Index of outlier values in two-dimensional numpy array. This method identifies the lower and upper bounds of the outliers by using the 75th percentile (Q3) and the 25th percentile (Q1) of the data.com3 ways to remove outliers from your data – GitHub Pagesocefpaf. I have created a function that will remove outliers from a series of data.std(data) filtered = [e for e in data if (u – 2 * s < e < . The shape of the data is usually around 1000x8, but can also be transposed without any problem. In this guide, we’ll explore different outlier removal .arange(12) + 1 >>> mask = np. I would be glad if someone could explain me further. A specific requirement is that the curve wraps around (i.Firstly we loaded all the data needed for the analysis using Numpy.We can then define and remove outliers using the z-score method or the interquartile range method: Z-score method: #find absolute value of z-score for each observation.DataFrame({‚Data‘:np.
outlier-utils · PyPI
If you have separate 1D arrays, X and y, and the same for the outliers, you can zip them into tuples and add them to a set and then subtract the outliers from the set: points = set(zip(X, y)) outliers = set(zip(outlier_x, outlier_y)) X_new, y_new = zip(*(points – outliers))
Outliers Pruning Using Python
Append elements at the end of an array. The interquartile range (IQR) is the difference between the 75th percentile (Q3) and the 25th . So first, calculate your initial statistics: .

Is there a shortcut of how I can remove the corresponding z-scores from my dataset? I played around with numpy.ones(len(arr), . Also, plots like Box plot, Scatter plot, and Histogram are useful in visualizing the data and its distribution to identify outliers based on the values .
How to Find Outliers in NumPy Easily?
Let’s remove rows where Z value is greater than 2. This means verifying that the data still accurately reflects the case you’re analyzing.where((data > . Often it is preferable to use a boolean mask.where(), but it returns only certain values if compared above a threshold. Ask Question Asked 5 years, 11 months ago. Loosely, an outlier is considered an outlier if it +/- .you should remove outliers from your data before any plot or fitting : h=sorted(df_distr[‚Distance‘]) out_threshold= 150.We can use the Z-Score method to identify and remove outliers from the Boston Housing Prices dataset: # Import required libraries from sklearn.Even though this question is very old now, I will still provide another answer based solely on numpy and scipy although the latter is rather optional.datasets import load_boston import numpy as np # Load . I have the following signal to process ( raw data ): I would like to process the signal to eliminate outliers to obtain a smooth curve.5) upper_bound = q3 + (iqr * 1.percentile(data, [25, 75]) iqr = q3 – q1. For outlier detection on each row I decided to simply use 5th and 95th percentile (I know it’s not the best statistical way): Code what I have so far: P = np.zscore(data)) #only keep rows in dataframe with all z-scores less than absolute value of 3.import numpy as np def reject_outliers(data): m = 2 u = np.randn(2e6, 10) def . This can be done by creating a new . data_clean = data[(z<3).For the given data, I want to set the outlier values (defined by 95% confidense level or 95% quantile function or anything that is required) as nan values.
Without going into too much detail, the z-score is a . How to retrieve rows with outliers: df [df [‚SAL_excl‘]. Libraries like SciPy and NumPy can be used to identify outliers. Viewed 2k times 1 I am trying to create a function that will parse through an array of values and then update the array without the values that are determined to be outliers by falling outside of the interquartile range. The outliers are then removed if they fall outside of these bounds. it is possible that new outliers appear as data has now new Q1/Q3/IQR due to the filtering.DataFrame(data, columns=[‚a‘,’b‘,’c‘,’d‘,’e‘,’f‘]) sns. threshold = data[dim].Fortunately, Python provides us with several powerful methods to identify and handle outliers effectively.Bewertungen: 4
numpy
47904781] If you plot this sequence, you’ll get the following figure: Here’s the code used to generate this plot: import numpy as np. Then we looked for the steps required for the outlier pruning/detection.To remove outliers from a numpy array in Python, one approach is to use the IQR (interquartile range) method.I believe the method you’re referring to is to remove values > 1.I have written a function that removes outliers from a dataset. def replace_outliers(data, dim=0, perc=0. While I feel like the conditions I . The larger it is, the less outliers are removed.scatter(reject_outliers(y))‘, it looks like the outliers are successfully getting dropped: .Function: def reject_outliers_iqr(data): q1, q3 = np. In this approach, we calculate the mean and standard deviation of the dataset and remove data points that fall outside a specified range (usually 2 or 3 standard deviations from the mean).Alternate solution, starting with 1D arrays.0 h=[i for i in h if i mean(data)) / np. If you have multiple columns in your dataframe and would like to remove all rows that . Outliers have an unnaturally high influence on the regression .Removal of Outliers with Z-Score. What are the libraries and plots we can utilize to detect and remove outliers in a data set for a data science project? A. I would suggest you edit your code so as to get the index of that cell and then pass it onto np. After removing outliers from your dataset, it’s important to ensure that the integrity of your data remains intact. This method identifies the lower and upper bounds of . So I tried temporary removing the last column and putting it back that . Finding outliers in linear regressions is a quite common and yet tricky task. Following is the my data and code that I am using right now. from scipy import stats.delete() works in an index based manner.std(data) Select every value from data except for the outliers . In this approach, we calculate the mean and standard .merge([outliersMask, outliersMask, outliersMask]) # Apply the adaptive filter: cleanedImage = np. df[‚x_to_scale‘] = (100*(x – np.99): # calculate percentile. outliersThere are several ways to remove outliers, including: Filtering: One option is to simply filter out the outliers from the dataset.You can create your own function. It works using the z-score and it works for elements of 1d, for example; # usage remove_outliers(data) [10 99 12 15 9 2 17 15]—->[10 12 15 9 17 15] Remove outliers from numpy array, column wise. Here’s how to implement the standard deviation . Once the outliers are removed, calculating the mean is as simple as calling the .For each column except the user_id column I want to check for outliers and remove the whole record, if an outlier appears.# Removing Outliers with IQR non_outliers = data_with_outliers[(data_with_outliers >= lower_bound) & (data_with_outliers <= .Removing outliers can be done in a number of ways.pandas - How to remove Outliers in Python? - Stack Overflowstackoverflow. This example uses the z-score method for removing the outliers.mean(data) s = np.Bewertungen: 2 boxplot (data=df, x=’year‘, y=’SAL_excl‘) NB. the beginning of the curve should be .mean() function on each column of the DataFrame, or using the .normal(size=200)}) # Index List of Non-Outliers nonOutlierList = Remove_Outlier_Indices(df) # Non-Outlier Subset of the Given .How to use simple univariate statistics like standard deviation and interquartile range to identify and remove outliers from a data sample.tolist() output: [ 3 2 14 2 8 4 3 5] If you are not sure of the percentile cut-off and are looking to remove outliers: You can adjust your cut-off for outliers by adjusting argument m in function call. Python (version 3.boxplot(x=variable, y=value, data=pd.but that’s looking at the culled y vector relative to the index, rather than the datetime vector x as in the above plot.Removing Outliers. import numpy as np, matplotlib.And I already have a function to remove a complete rows when one of its data is an outlier, that I took from here: Removing outliers in each column (and corresponding row) But the function is normalizing all the columns and I dont want it to affect the last one.I think you should see Numpy Documentation and refer to the first line where they specifically say that it returns all the elements that don’t conform with arr[obj], this means that numpy. In this example, we sets a threshold value of 2 and then uses NumPy’s .First off, it seems like the curve you’re fitting is not going to fare much better by just removing outliers. import numpy as np. Modified 5 years, 11 months ago. Use the interquartile range. Let f be a 1-D numpy array of . Regarding outlier removal, take a look at RANSAC (RANdom SAmple Consensus), which is an algorithm that attempts to regress a curve that is robust .There are two common ways to do so: 1.If you have multiple columns in your dataframe and would like to remove all rows that have outliers in at least one column, the following expression would do that in one shot: import pandas as pd.quantile(perc) # find outliers and replace them with max among . # perc -> percentile that define the exclusion threshold.When I run ‚px. Here are steps to validate data integrity post outlier removal: Then we went for the practical implementation, where we detected the outliers and removed them in both N-Dimensional and uncertain curve data using various statistical measures.A way to spot outliers is the follow: Compute the z-score: d = (data – np.where(augmentedBinary == (255, 255, 255), filteredImage, . As the debugging text indicates, the vector is shortened because the outlier values are dropped rather than replaced. # dim -> dimension to which apply the filtering.
Fehlen:
Taming Outliers: A Guide to Outlier Removal in Python
How to Remove Outliers in Python • datagy
