What Is The Formula For Gradient Descent?
Di: Luke
Gradient Descent (GD) is a widely used optimization algorithm in machine learning and deep learning that minimises the cost function of a neural network model .
The Gradient Descent Algorithm
Figure — 40: Gradient descent algorithm 4. Like before, the algorithm will update the parameter values by taking the partial derivative of the cost function with . Statistics way of computing line of best fit: .In Andrew Ng’s machine learning course, he introduces linear regression and logistic regression, and shows how to fit the model parameters using gradient descent and Newton’s method. I know gradient descent can be useful in some applications of machine learning (e. 4- You see that the cost function giving you some value that you would like to reduce.The same gradient descent algorithm is the one we will be using in logistic regression and a lot of things will be similar with the above mentioned post. SGD would be an extreme case when the mini-batch size is reduced to a single example in the raining dataset. In this mesmerizing gif by Alec Radford, you can see NAG performing arguably better than CM (Momentum in the gif).Using momentum with gradient descent, gradients from the past will push the cost further to move around a saddle point. Choose a value for the learning rate η ∈ [a,b] η ∈ [ a, b] Repeat following two steps until f f does not change or iterations exceed T. This variable is either or ( ).The formula for the gradient descent algorithm is as follows.Gradient descent is a tool to arrive at the line of best fit.Gradient descent works with convex functions and finds the fewest and most accurate amount of steps toward the lowest point of a curve, optimizing the path.
Linear Regression using Gradient Descent
Schlagwörter:Learning Rate in Gradient DescentNiklas DongesOccupation:FounderSchlagwörter:Machine LearningLinear Regression Gradient DescentSchlagwörter:Loss Functions and Gradient DescentRun_Gradient_Descent Step — 4: Next, we find the partial derivatives of .The goal of Gradient Descent is to minimize the objective convex function f (x) using iteration. where it is used to minimize a function by gradient descent. v θ ← μv + η∇θJ(θ) ← θ − v v ← μ v + η ∇ θ J ( θ) θ ← θ − v.Artificial neural networks (ANNs) are a powerful class of models used for nonlinear regression and classification tasks that are motivated by biological neural computation.Gradient descent is an optimization algorithm used to find the values of parameters (coefficients) of a function (f) that minimizes a cost function (cost).Schlagwörter:Gradient Descent Machine LearningLinear Regression Gradient Descent Gradient descent is a first-order iterative optimization algorithm for finding the minimum of a function (commonly called loss/cost functions in machine learning and deep learning).This step-by-step tutorial on gradient descent explains a fundamental optimization algorithm at the heart of AI. To improve a given set of weights, we try to get a sense of the value of the cost function for weights similar to the current weights (by calculating the gradient).New Weight = Old Weight — a small change in W.Schlagwörter:Gradient Descent Machine LearningConvex Function
What is the maths behind the descent rate calculation?
This is the point we’re trying to reach using gradient descent. In the bottom, slightly to the left, there is the random start point, corresponding to our randomly initialized parameters (b = 0.Schlagwörter:Convex FunctionUse of Gradient Descent How to use stochastic gradient . In particular, we restrict the functions to the class of overparameterized two-layer neural .To find the w w at which this function attains a minimum, gradient descent uses the following steps: Choose an initial random value of w w. In other words, we say that a minima is . What Is a Gradient? How gradient descent works.

Here w1,w2, w3 are the weights of there corresponding features like x1,x2, x3 and b is a constant called the bias. Starting with a simple Machine Learning Model (The minimum is where the star is, and the curves are contour lines. Convex function v/s Not Convex function. by how many units does the river need to .Schlagwörter:Gradient Descent Machine LearningRun_Gradient_Descent
Gradient Descent Algorithm Explained
Gradient Descent on Cost .Schlagwörter:Machine LearningGradient Descent For Two VariablesGradient Latex In coordinate-free terms, the gradient of a function () may be defined by: = where is the total infinitesimal change in for an infinitesimal displacement , and is seen to be maximal when is in the direction of the .You may recall the following formula for the slope of a line, which is y = mx + b, where m represents the slope and b is the intercept on the y-axis. So now, we can continue deriving the Gradient descent formula for multiple training examples. Image: Shutterstock / Built In.Here’s the formula for gradient descent: b = a – γ Δ f (a) The equation above describes what the gradient descent algorithm does.The first stage in gradient descent is to pick a starting value (a starting point) for \(w_1\). By understanding how gradient descent .Schlagwörter:The Gradient Descent AlgorithmMachine LearningConvex OptimizationThe gradient descent update rule is given as follows : Image Source: Created by Author.Substitute back in , we finally have the gradient descent formula for a single training example as follows: (20) I hope that’s not too difficult to follow.
Gradient descent (article)
-> α : Learning Rate of Gradient .

A starting point for gradient descent . In the cost surface shown earlier let’s zoom into point C. Our equation of gradient descent until now, we have used, So, if dL/dW is 0, the weights remain the same and we get stuck in .For an explanation about contour lines and why they are perpendicular to the gradient, see . The starting point doesn’t matter much; therefore, many algorithms simply set \(w_1\) to 0 or pick a random value. Here is a working example of gradient descent written in GNU Octave: .
A Gentle Introduction To Gradient Descent Procedure
Just like the gradient descent lemma for exact gradient descent, the stochastic gradient descent lemma guarantees descent in function value, in exp ectation, when ?> 0 is .
Solving for regression parameters in closed-form vs gradient descent
-> θ j : Weights of the hypothesis. The difference between gradient descent and stochastic gradient descent.
Gradient Descent — Machine Learning Works
Gradient Descent helps to find the degree to which a weight needs to be changed so that the model can eventually reach a point where it has the lowest loss.In the section of momentum gradient descent: The equation v1 =λv0 +α∇f(x0) x1 = x0 + v1 The first equation, it will be gradient steepness, So, the correction is: v1 =λv0 – α∇f(x0) to .2- Using them you calculate values of thetas and draw the figure using hypothesis equation. But if a gradient descent algorithm once attains the local minimum, it is nearly impossible to reach the global minimum. ( B ) Sum Rule: Source: . To find a local .To do this, we create a linear function f (x) = b + mx f (x) = b + mx that has a minimal mean squared error (or MSE) with regard to our data points. Before we dig into gradient descent, let’s first look at another way of computing the line of best fit.Now, if we consider x as the weights and y=f (x) as the loss function, dL/dW=0.Schlagwörter:Gradient Descent Machine LearningDeep LearningArtificial IntelligenceGradient Descent is an optimizing algorithm used in Machine/ Deep Learning algorithms.
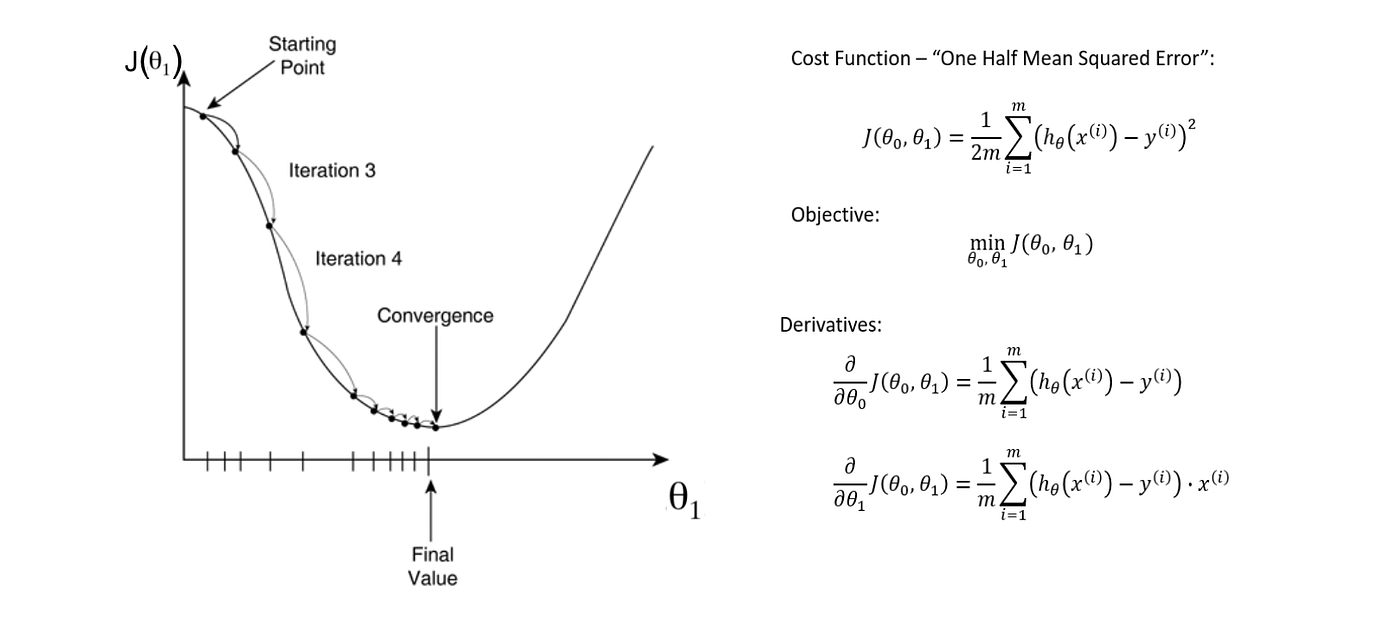
Usually the iterative of the weight . But then I also found this article where the momentum is .Edit on GitHub. The formula below sums up the entire . Figure — 41: Updating the parameters using the gradient descent algorithm 4.Gradient descent is like dropping a marble into an oddly shaped bowl, wheras gradient ascent is releasing a lighter than air balloon inside an oddly shaped dome-tent. Gradient descent is best used when the parameters . Its importance is that it gives flexibility.Formula: Gradient Descent Formula., backpropogation), but in the more general case is there any reason why . Gradient Descent with Momentum and Nesterov Accelerated Gradient Descent are advanced versions of . We learn how the gradient descent algorithm works and finally we will implement it on a given data set and make predictions.Schlagwörter:Deep LearningMachine LearningLinear Regression Gradient Descent
Gradient Descent Algorithm
The reverse gradient direction is just a search direction, based upon very local knowledge of the function f (w, x).analyticsvidhya.Gradient descent (GD) is an iterative first-order optimisation algorithm, used to find a local minimum/maximum of a given function.Appendix 1 – A demonstration of NAG_ball’s reasoning. Suppose we have a function f (x), where x is a tuple of several variables,i. Gradient descent ¶., So the updated equation is, How do we calculate ΔW? That is . In the center of the plot, where parameters (b, w) have values close to (1, 2), the loss is at its minimum value. Step — 4: We will use the formula given in Step — 3 to find the optimal values of our parameters θ1 and θ2.
An overview of the Gradient Descent algorithm
comGradient Descent Algorithm | How Does Gradient Descent . So, using such an equation the machine tries to predict a value y which may be a value we need like the price of the .2) to acquire the descent rate. We repeatedly calculate this until convergence. Introduction to Gradient Descent.The form of the Simple Linear Regression model.The descent rate calculation states that descent rate is calculated by ‚groundspeed / 2 * 10‘.
We do this by calculating 1) the gradient which gives us the direction of the slope and 2) calculating our step-size (i.The gradient descent procedure is an algorithm for finding the minimum of a function.Geschätzte Lesezeit: 9 min
Gradient Descent For Machine Learning
This formula represents the probability of observing the output of a Bernoulli random variable.x_n) that give us the minimum of the .Gradient descent is an iterative method.Schlagwörter:Gradient Descent Machine LearningThe Gradient Descent Algorithm
Gradient Descent Algorithm — a deep dive
For mini-batch gradient descent, the mini-batches are usually powers of two: 32 samples, 64, 128, 256, and so on. In this tutorial you can learn how the gradient descent algorithm works and implement it from scratch in python.

Another document stated that the ground speed should be multiplied by 5 (or more accurately 5. By iterating over the training samples until convergence, we reach the optimal parameters leading to minimum cost.comEmpfohlen auf der Grundlage der beliebten • Feedback
Gradient Descent Tutorial
As a result, we can use the same gradient descent formula for logistic regression as well. Choose the number of maximum iterations T. Jessica Powers | Mar 27, 2023.
Gradient Descent With Momentum
In vector calculus, the gradient of a scalar-valued differentiable function of several . The following figure shows that we’ve picked a starting point slightly greater than 0: Figure 3. Once a new point . Moreover, we’ve .While looking around on the web, it seems to be more common to use not only the last 2, but rather the entire history of gradients, i. -> i : Feature index number (can be 0, 1, 2, . The disadvantage of . Recall, gradient descent is based on the Taylor expansion of f (w, x) in the close vicinity of w, and has its purpose—in your context—in repeatedly modifying the weight in small steps. Also, suppose that the gradient of f (x) is given by ∇f (x)., x = (x_1, x_2, .Gradient Descent. Gradient Descent is a method used while training a machine learning model.Gradient descent algorithm is an iterative process that takes us to the minimum of a function (barring some caveats). Gradient Descent for Multiple Training Examples It squeezes any real number to . So, reading that first will lead to better . The general idea behind ANNs is pretty straightforward: map some input onto a desired target value using a distributed cascade of nonlinear transformations (see . In this article, we’ve learned about logistic regression, a fundamental method for classification. It is simply used to find the values of a functions parameters (coefficients . Suppose we have a convex cost function of 2 input variables as shown above and our goal is to minimize its value and find the value of the parameters (x,y) for which f(x,y) is minimum.Schlagwörter:Gradient Descent Machine LearningDeep Learning We start with some set of values for our model parameters (weights and biases), and improve them slowly.Descent: To optimize parameters, we need to minimize errors.Schlagwörter:Gradient Descent Machine LearningThe Gradient Descent Algorithm by how many units does the river need to move in a particular direction) From the above formula, there are two things that we can set on our own; α and the current position of Ɵ.2 value is found by finding the gradient for 3 NM for 1000 feet (based on the 3:1 glide ratio), which is 5.Now, it tries to devise a formula, like say for a regression problem, Equation 1. -> h θ(xi) : predicted y value for i th input. Some Basic Rules For Derivation: ( A ) Scalar Multiple Rule: Source: Image created by the author. What the gradient descent algorithm does is, we start at a specific point on the curve and use the negative gradient to find the direction of steepest .Written by Niklas Donges. let’s do it!. 3- You calculate the cost using cost function, which is the distance between what you drew and original data points. With gradient descent, if the learning rate is too small, the weights will be updated very slowly hence convergence takes a lot of time even when the gradient is high.
An Introduction to Gradient Descent and Backpropagation
Since we already have an idea of what the gradient descent formula does, let’s dive right into it.For Batch gradient descent, the batch size is the total number of samples in the training dataset.We study minimax optimization problems defined over infinite-dimensional function classes. That is b is the next position of the . We want to find the value of the variables (x_1, x_2, . This method is commonly used in machine learning (ML) and deep learning . ΔW can replace a small change in W . Let’s see how we got this formula. edit: Most DL frameworks seem to implement this version. The difference is only in where marble/balloon is nudged, and where it ultimately stops moving. Then we move in the .Gradient Descent in Machine Learning: Python Examples – . The aim of the gradient descent algorithm is to reach the local minimum (though we always aim to reach the global minimum of the function. It is an optimization algorithm, based on a convex function, that tweaks it’s parameters iteratively to minimize a given function to its local minimum. First we look at what linear regression is, then we define the loss function. Gradient Descent can be summarized using the formula, Image Source: Created by Author.
- What Is The Maximum Capacity Of Sql Server?
- What Is The Difference Between Electrical And Electronic?
- What Is The Music In The Dolce
- What Is The Black Sabbath Motorcycle Club Nation?
- What Is The Best Network Card For Lenovo Thinkpad T420I?
- What Is The Name Of The Town In Fallout 3?
- What Is The Faderpro Rekordbox Limited Time Offer?
- What Is The Fastest Sold-Out Concert In History For Wanna One?
- What Is The Peak-Notch Filter Block?
- What Is The Hex Value For Anthracite?